推文502
背景
前几周,运营做营销活动推文,推文后,我们我们没有收到任何的系统报警。业务反馈,用户进不去页面,有的还报502。what?
抓紧时间排查。
-
cpu 正常
-
网络链接正常(单机ng的有效链接1000,单机流量200mb)
-
链路请求正常(10分钟内超过2秒的接口不到1000条,大部分还都是银行卡相关的)
-
数据库也正常
都正常啊,怎么就502了?看下ng的超时日志,最近10分钟内,单机也就几百个,不应该怎么慢啊。
不对,突然想起来在打开后端系统的有点卡顿。
难道是网络带宽耗尽了?
马上找运维看了下公网带宽,才200mb,而且是弹性的,也没问题。又重新想了整体的链路。我们的链路如下:

从ng到业务系统,没有任何问题,三种监控手段,没有一个报警。
那只有前面了
-
外网入口,没问题
-
高防,没问题(后端反馈给高防,10分钟有将近2万条502)
-
waf(当时安全负责人请假,没有看到这块)
然后,我们让运维一个个的节点给我们看流量和使用率。
最后发现在waf,cpu 使用率高达80%,但是load却高达8~12,tcp链接数达到了17万。
最终定位到问题。
原因是前段时间进行了降配,waf平常流量的情况cpu使用率能达到30%到40%,推文+营销流量翻了好几倍,导致waf的cpu负载过高,在waf那一层就将链接拒了。其次开发从公有云迁移专有云时,把外网的健康检查也给去了。
一次token失效查询
我们系统的逻辑是这样的。
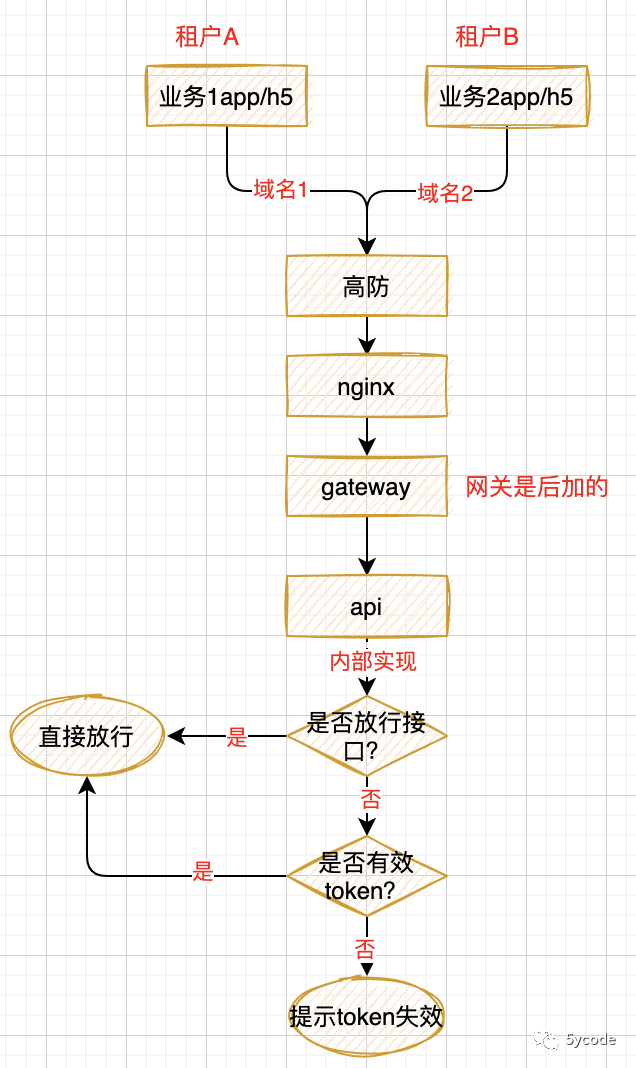
最开始我们的系统是不支持租户的,只有租户A 的业务,在2018年我们进行了租户化改造。当时定义的规范是:
-
业务数据进行租户化隔离(通过租户路由到不同的数据库);
-
公共配置数据共源;
背景:在2019年的时候,我们孵化了业务B,一直到今年我们的业务核心还是在业务A 渠道,业务B渠道,没怎么管,流量99.9%都是在业务A,在业务B上线以后做过数据初始化工作;
大概在9月份的时候,业务人员在走业务A流程的时候反馈一个问题,没登录提示token失效,登录以后都正常,当时测试验证的时候没有复现,再说从本身的业务逻辑来说,用户不登录在我们这确实什么都没法操作,当时这个问题就搁置了。然后9月底流量开始往业务B上导,
自从推文502后,就开始让技术分析各种可能影响性能的问题。
从数据里发现了一个不需要token验证的接口周期性的出现token失效,这个绝对不正常。
然后我们开始排查:
-
梳理代码,发现图上的逻辑;
-
当时第一个想法是不是主从数据库不一致的问题,或者哪个数据库的磁盘有问题导致的?开发确认都没有问题;
-
当时还是不放心,就让加了日志验证;
-
同时继续撸代码,发现缓存的时候做了序列化的操作,而且还有数据还嵌套了,当时就想起之前遇到的一个问题,fastjson序列化数据丢失(后来想想也不应该,如果丢失就不会周期性的出现),同时猜测还有可能是反序列化的时候丢失;
-
同时在想,是不是哪里有定时任务在更新这个缓存导致的(排查代码,发现没有,甚至还更换缓存key的操作);
-
先不管,先把日志加上,上线观察下日志;
-
上完线在等数据样本的时候,又回想了下,以上那几个问题的可能性微乎其微,如果有那就是必现的问题;
-
然后进去kibana去看数据,点开一条数据,无意间瞅到了租户id,就想这个问题是共性问题?还是只是某租户上的?
-
然后发现出问题的都是业务A的租户id
-
然后观察到出问题之前调用写入的都是业务B
-
这个时候有点眉目了,翻代码,发现api系统把配置表也做了租户化;
-
从DB里查询时按租户区分,往redis写和查询时未加租户id;
-
业务B从19年到现在表里的数据没有任何改动;
-
业务A一直在往里加数据,两边差了近30条;
-
先把租户A的数据同步到租户B
-
后续再把公共配置表抽出来,全局共用
签章优化
我们做的信贷业务,之前因为历史原因,机构有三个签章由我们调用机构完成(按业务结构我们不应该关注这个,应该由机构统一处理);
最近单量较大,机构签章这块经常超时,放款的时效性不能保证;
和开发聊了下这块的业务;
业务逻辑也很简单,如下图
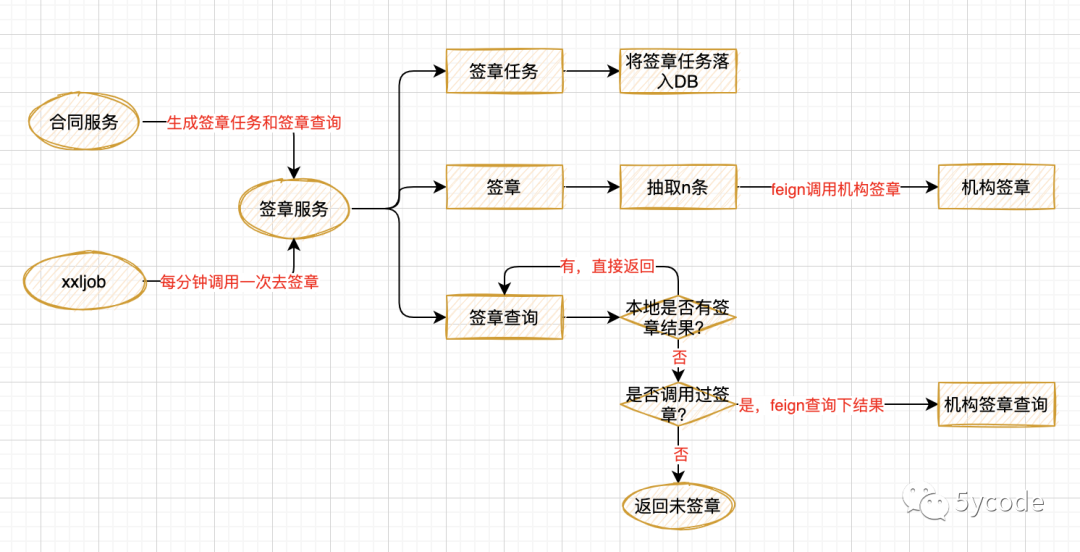
-
合同服务调用生成任何和签章结果查询
-
xxljob 每分钟调用抽取任务去签章
-
外部调用都是通过feign调用
-
项目里配置的hystrix是feign的全局策略
当时这里有两个问题:
-
分布式调度每分钟批量去签章,要么处理能及时处理,然后cpu空闲,要么不能及时处理,任务越压越多;
-
解决方案一:直接用消息队列去承载任务,将定时去掉,这样通过高峰填谷的方式充分利用cpu以及后端服务的性能,能及时处理(这个改造需要相关系统的配置);
-
解决方案二:动态调整抽取任务数,每次任务处理完以后,计算任务的处理时效,最大程度的利用cpu资源(这个改造需要动态适应,逻辑较多);
-
解决方案三:任务启动以后直接while循环,处理一批以后接着处理下一批次,没有任务就休眠一段时间,分布式调度也不去掉,只是改为任务监测,发现任务停止了,启动任务;
-
以上三个方案都是临时方案,直至机构将签章任务迁移走;
-
项目中配置的feign的hystrix
-
解决:只有签章才用hystrix,查询不做限制(毕竟成功后会落入本地库)
-
当签章超时时,任务积压,会堵塞签章查询(因为异常的签章会走feign调用机构) ,会阻塞查询;
-
利用hystrix熔断签章,同时也会熔断查询
后续针对这种资源共享的地方都得好好的排查下,特别是涉及到以下:
-
线程池还是
-
数据源(核心与非核心共用,saas业务共用不区分)
-
定时任务
-
熔断策略,一定要是接口维度的,禁止使用全局共享

