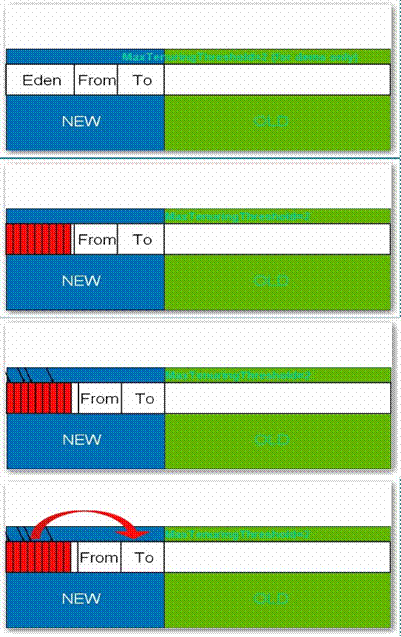
分代垃圾回收流程示意 选择合适的垃圾收集算法 串行收集器 用单线程处理所有垃圾回收工作,因为无需多线程交互,所以效率比较高。但是,也无法使用多处理器的优势,所以此收集器适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。可以使用-XX:+UseSerialGC打开。 并行收集器 对年轻代进行并行垃圾回收,因此可以减少垃圾回收时间。一般在多线程多处理器机器上使用。使用-XX:+UseParallelGC.…
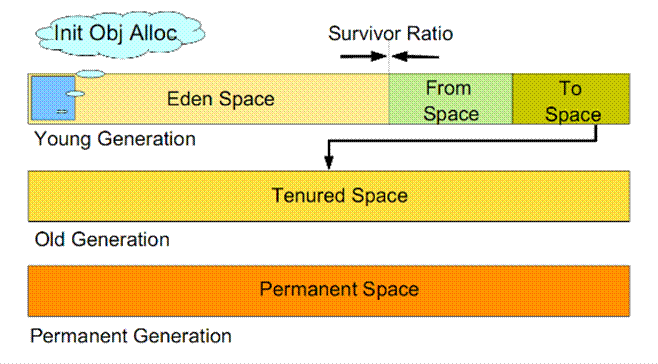
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。 在Java程序运行的过程中,会产生大量的对象,其中有些对象是与业务信息相关,比如Http请求中的Session对象、线程、Socket连接,这类对象跟业务直接挂钩,因此生命周期比较长。但是还有一些对象,主要是程序运行过程中生成的临时变量,这些对象生命周期会比较短,比如:String对象,由于其不变类…
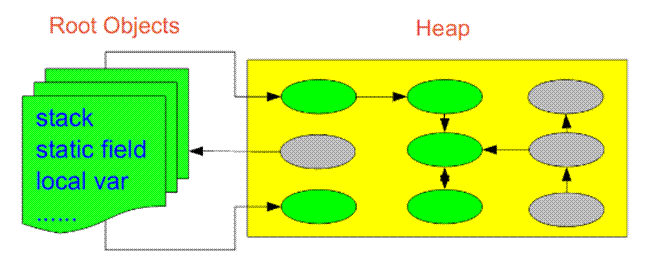
如何区分垃圾 上面说到的“引用计数”法,通过统计控制生成对象和删除对象时的引用数来判断。垃圾回收程序收集计数为0的对象即可。但是这种方法无法解决循环引用。所以,后来实现的垃圾判断算法中,都是从程序运行的根节点出发,遍历整个对象引用,查找存活的对象。那么在这种方式的实现中,垃圾回收从哪儿开始的呢?即,从哪儿开始查找哪些对象是正在被当前系统使用的。上面分析的堆和栈的区别,其中栈是真正进行程序执行地方,所以要获取哪些对象正在被使用,则需要从Java栈开始。同时,一个栈是与一个线程对应…
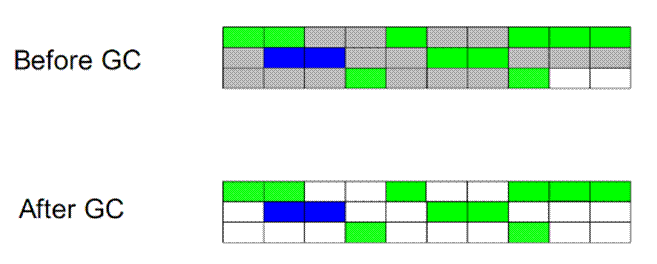
可以从不同的的角度去划分垃圾回收算法: 按照基本回收策略分 引用计数(ReferenceCounting): 比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。 标记-清除(Mark-Sweep): 此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,…

Java对象的大小 基本数据的类型的大小是固定的,这里就不多说了。对于非基本类型的Java对象,其大小就值得商榷。 在Java中,一个空Object对象的大小是8byte,这个大小只是保存堆中一个没有任何属性的对象的大小。看下语句: Objectob = new Object(); 这样在程序中完成了一个Java对象的生命,但是它所占的空间为:4byte+8byte。4by…
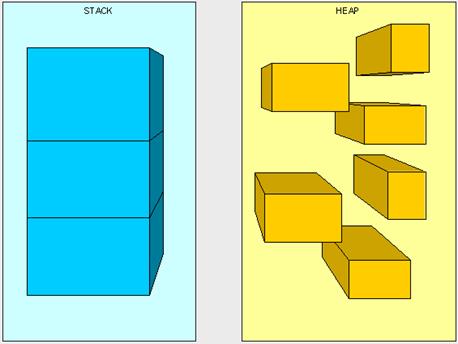
数据类型 Java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。 基本类型包括:byte,short,int,long,char,float,double,Boolean,returnAddress 引用类型包括:类类型,接口…
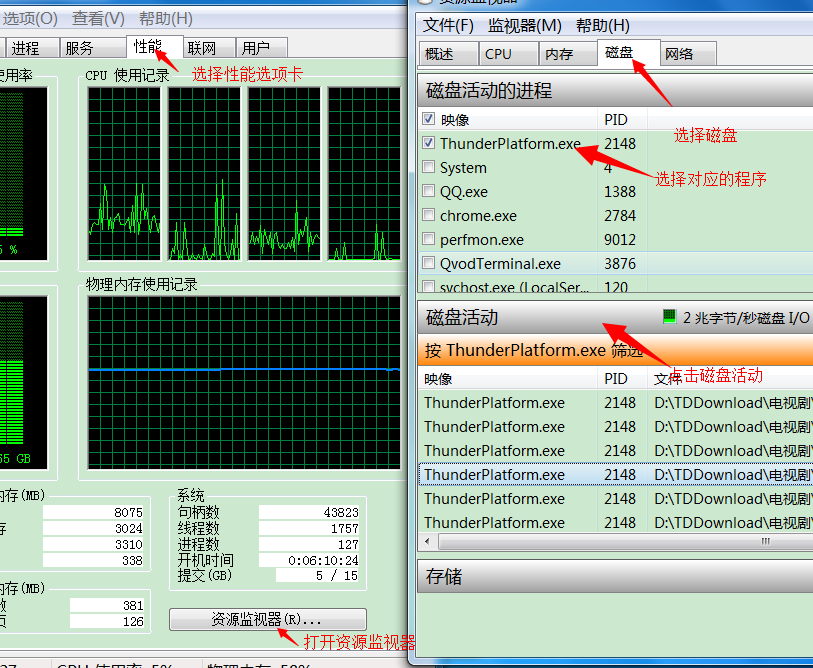
迅雷在那边开着,发现蹭蹭的网上上传数据,每秒1mb左右的速度。我想知道它上传了什么东西,于是就百度了下 打开Win7任务管理器,切换到性能选项卡,点击右下角资源监视器,这就是一个高级版的任务管理器了,可以很直观的查看本机的各种状态,点击磁盘,展开磁盘活动列表,适当调整好宽度,单击按读取速度排序,一般上传的速度很快的,基本上第一个就是Thunderplatform.exe或者Thunder.exe,这就是迅雷的进程了,或者你装的快车,电驴什么的,然后看文件那一列…
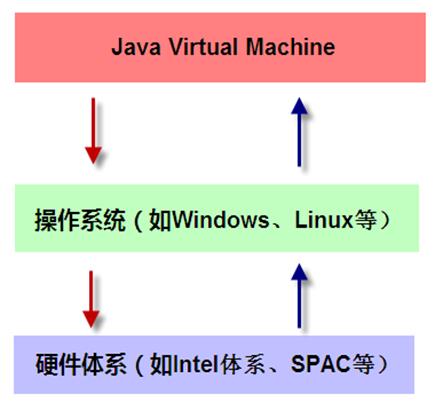
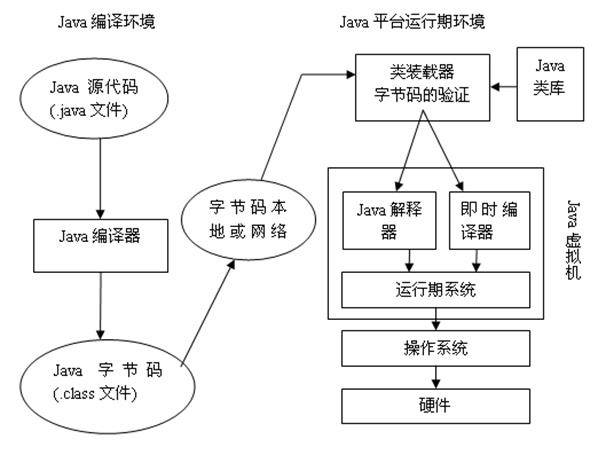
Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,墙外面的人想进去,墙里面的人却想出来。 概述: 对于从事C、C++程序开发的开发人员来说,在内存管理领域,他们即是拥有最高权力的皇帝又是执行最基础工作的劳动人民——拥有每一个对象的“所有权”,又担负着每一个对象生命开始到终结的维护责任。 对于Java程序员来说,不需要在为每一个new操作去写配对的delete/free,不容易出现内容泄漏和内存溢出错误…