
生成脚手架 随着新框架的不断稳定(同时也带来了不错的收益),新的项目以及重构项目不断的往新框架上切,基于这个原因,要把新框架整一个脚手架。 脚手架中包含了demo(为了学习而框架,实际开发中会有一些便利性的调整) 注意事项 依赖maven环境,必须配置MVAVA_HOME 依赖jdk环境(一定要jdk,不要jre) maven-archetype 的模板使用velocity 引入插件以及自定义配置文件 先找一个可以跑起来的demo,在pom文件中引入脚手架的maven plugin 我的工程结构如下: 项目地址:h…
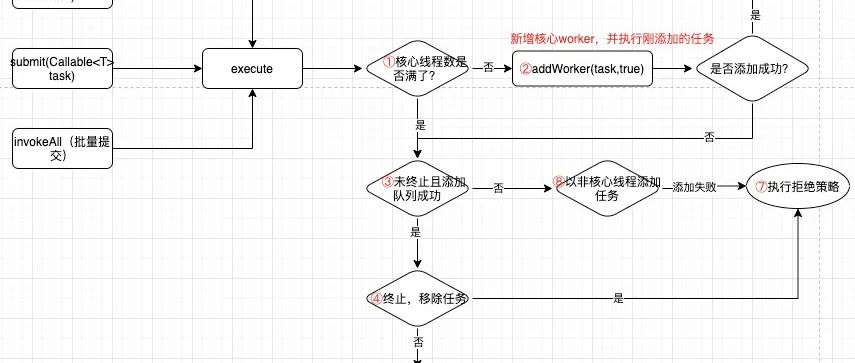
这可能是最简短的线程池分析文章了。 顶层设计,定义执行接口 Interface Executor(){ void execute(Runnable command); } ExecutorService,定义控制接口 interface ExecutorService extends Executor{ } 抽象实现ExecutorService中的大部分方法 abstract class AbstractExecutorService implements ExecutorService{ //此处把Execut…
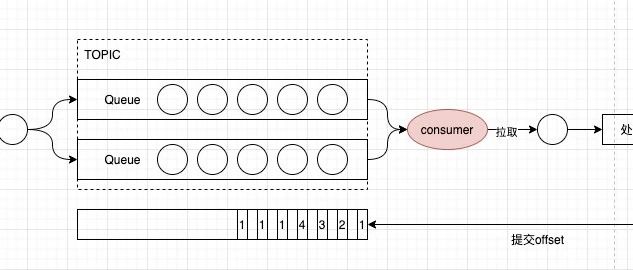
之前一直用kafka,也了解了kafka的本身的一些机制,包括顺序读、顺序写、零拷贝、分治、水位等。但一直没详细的了解下kafka消费端是如何工作的。 趁着假期分析下,环境如下: <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.12.RELEASE</v…
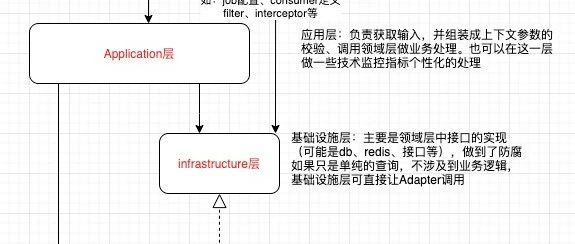
没错,又来了,一个项目的结束,就会复盘并完善下。 传统开发的弊病: 通过事务脚本模式来开发需求; 开发人员热衷于技术并通过技术手段解决问题,而不是深入思考和设计业务的走向; 过于重视数据库,围绕数据库和数据模型进行建模,按数据流程进行建模; 按技术视角进行业务命名,导致后续迭代以及人员更替时,产品和技术无法对齐; 随着业务的发展,到后续业务、技术无法沟通,各种不理解; 业务希望技术出排期,技术得撸代码,耗费精力; 代码开发的过程中技术和业务耦合,一个场景一个服务,代码流水线; 因为技术的问题会导致业务流程的中断,导…
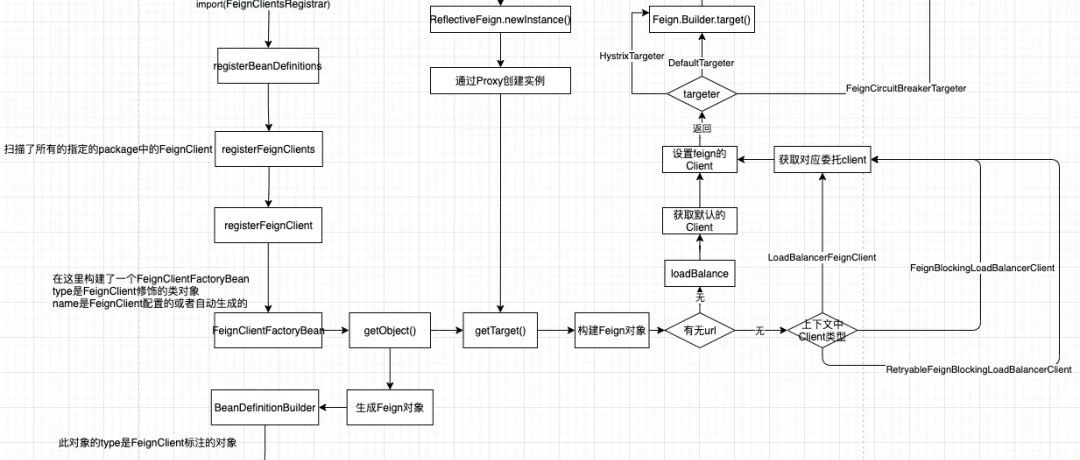
基于springcloud的灰度实现方案(一) 基于springcloud的灰度实现方案(二) @Configuration配置加载分析 之前介绍了灰度方案以及实现,分析feign调用的时候,有点不太尽兴,这次再丰富一下。 首先,我们在feign调用时,使用了FeignClient注解。 #接口调用 @FeignClient("demo-service") public interface DemoServiceFeginClient { } # 开启feign @EnableFeignClie…
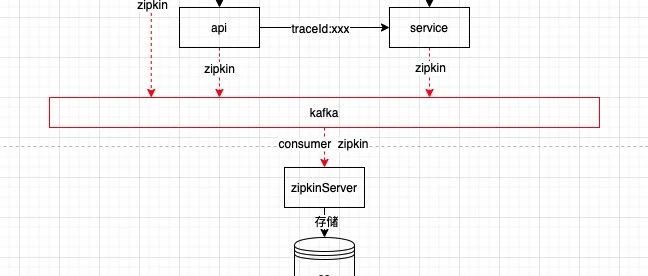
背景 项目DDD重构后,所有依赖重新整理,试运行期间发现链路追踪的抓取信息不够丰富,就翻下原来的项目源码,再看下对应的改造下。 环境依赖 kafka elasticsearch 7.10.0 (jdk11) Kibana 7.10 zipkin server sleuth 随着微服务的应用,我们运维系统时面临以下问题 真实情况的请求链路是什么? 链路请求过程中每个耗时了多少? 请求的参数以及每个系统的响应是什么? 分布式链路追踪解决了以上这些问题(当然需要自己手动扩展下) 分布式链路追踪(Distributed T…
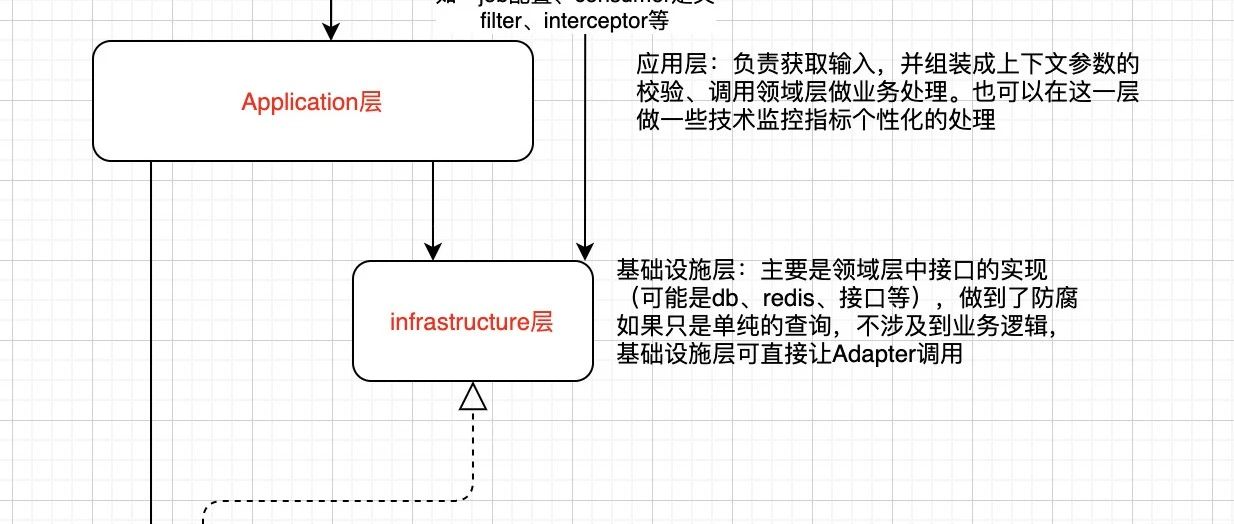
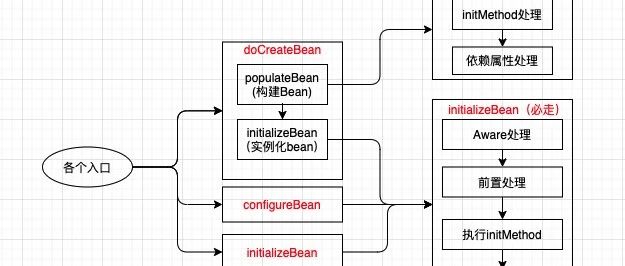
分享一个DDD的应用框架,写了一个简单的demo。 已经在在生产实践。 git地址:https://github.com/yxkong/ddd-framework 框架结构如下: 项目结构如下: 示例流程图: 简单说明: 只启动一个应用在adapter层启动; 接口请求到adapter层,调用DistributeController; controller层做上下文转化以及调用application层; application层进行模型依赖构建,以及领域执行前后的特殊处理; domain层进行了业务逻辑实现(和技术…

在灰度系列中《基于springcloud的灰度实现方案(二)》,之前规则适配使用数据库+策略模式实现,单个规则还好,多个规则,各种场景使用,还是稍微有点欠缺。就想着用java规则引擎来解决这个问题。 之前在项目中使用过drools,比较重,初始加载复杂,首次执行效率较低,最好预热一下,其次分布式规则处理时的一致性也得自己把控; 之前就了解过aviator,这次就直接用了。 相关资料 # 官网地址https://github.com/killme2008/aviator# 开发文档https://www.yuque.…
