持久化介绍:
redis的持久化有两种方式:
- rdb :可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)
- aof : 记录redis执行的所有写操作命令
根据这两种方式,redis可以开启三种模式的持久化
- rdb
- aof
- rdb+aof
rdb
- rdb 是一个非常紧凑的文件
- rdb适合灾难恢复,主从复制
- rdb可以最大化redis的性能,rdb操作是会从主进程fork一个子进程;
本章节主要讲解rdb,aof保留到下一章节讲解。
在redis的配置文件 redis.conf 中这么一段这个配置
save 900 1 # 表示900秒内有一个键改动,就会执行rdb
save 300 10 # 表示300秒内有10个键改动,就会执行rdb
save 60 10000 # 表示60秒内有1万个键改动,就会执行rdb我先把rdb流程放这,咱们再继续看代码。
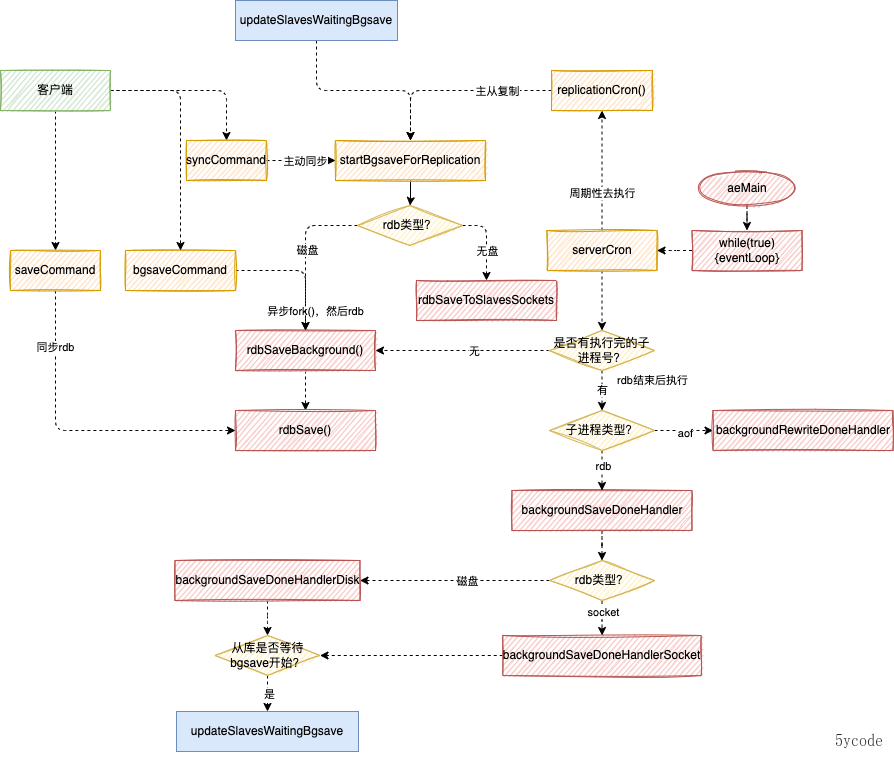
从流程上看rdb的发起主要有以下几个口子
- bgsaveCommand bgsave命令调用
- saveCommand save调用
- syncCommand 主从同步,直接执行命令
- serverCron 中定期检测
- replicationCron 主从定时
- UpdateSlavesWaitingBgsave 这块可以理解为新加了从节点,或者把从节点数据清空了,重新拉取
前两个都是为备份服务的,后面三个是为主从复制服务的。
从上面的图片可以看到,在进行主从同步的时候,有两种模式,一种是落盘后,主从同步,一种是不落盘直接网络传输。
rdb核心代码
落入磁盘的RDB
整个rdb磁盘持久化核心在rdbSave和rdbSaveBackground这里。
我们看下rdbSaveBackground 这个方法
/**
* 后台保存rdb
* 调用 serverCron、bgsaveCommand、startBgsaveForReplication
*
* 时间主要耗费在了fork() 产生虚拟空间表的过程
* @param filename
* @param rsi
* @return
*/
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
long long start;
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
//开始执行 rdb 备份前的dirty 值,保存在dirty_before_bgsave中
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
//创建一个pip管道,用于父子进程进行通信
openChildInfoPipe();
start = ustime();
//fork 一个子线程 给childpid
/**
* fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值
* - 在父进程中,fork返回新创建子进程的进程ID;
* - 在子进程中,fork返回0;
* - 如果出现错误,fork返回一个负值;
*
* 所以fork()成功,以后会执行两次
* == 0 的时候,是子进程执行
* == 1 的时候,是父进程执行
*
* 引用一位网友的话来解释fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,
* 父进程的fpid(p 意味point)指向子进程的进程id, 因为子进程没有子进程,所以其fpid为0.
*
* fork出错可能有两种原因:
* 1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
* 2)系统内存不足,这时errno的值被设置为ENOMEM。
* 创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
* 每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,
* 还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
*
* https://www.cnblogs.com/jeakon/archive/2012/05/26/2816828.html
*
* fork 为子进程创建了虚拟地址空间,仍与父进程共享同样的物理空间,当父子进程某一方发生写操作时,系统才会为其分配物理空间,
* 并复制一份副本以供其修改。
* proc文件系统为每个进程都提供了一个smaps文件
* - Shared_Clean:和其他进程共享的未被改写的page的大小
* - Shared_Dirty: 和其他进程共享的被改写的page的大小
* - Private_Clean:未被改写的私有页面的大小。
* - Private_Dirty: 已被改写的私有页面的大小
*
* 当子进程被fork出来时,空间是Private_Clean的,然后子进程对继承来的内存进行了修改,修改的部分就不能共享了。
* 修改的部分就是Private_Dirty
*
*
*/
if ((childpid = fork()) == 0) {
int retval;
/* Child */
//关闭自己不使用的父进程的资源
closeClildUnusedResourceAfterFork();
redisSetProcTitle("redis-rdb-bgsave");
//执行备份
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
//获取子进程修改的部分大小,相当于rdb耗费的内存
size_t private_dirty = zmalloc_get_private_dirty(-1);
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
//记录消耗内存的大小
server.child_info_data.cow_size = private_dirty;
//通过pipe和主进程通信
sendChildInfo(CHILD_INFO_TYPE_RDB);
}
//退出子进程,执行完成,为0 ,其他为1
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent */
//计算fork子进程花费的时间
server.stat_fork_time = ustime()-start;
//计算fork的速度
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
//周期性采样
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
//如果fork 失败,关闭管道
closeChildInfoPipe();
//记录备份状态为失败
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);
//记录rdb保存的开始时间
server.rdb_save_time_start = time(NULL);
//设置子进程id
server.rdb_child_pid = childpid;
//设置rdb类型 是到磁盘
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
updateDictResizePolicy();
return C_OK;
}
return C_OK; /* unreached */
}在这里主要是fork一个子进程,然后让子进程去执行rdb。具体子进程的创建以及备份分析不再讲解,请看上一篇。
在这里唯一会阻塞主进程的地方就是fork,虽然是操作系统的操作,只是创建一个页面映射表,如果数据量很大,也会有一定的阻塞(虽然时间极短),根据fork的原理,就有快照备份的说法。
在rdbSave中
int rdbSave(char *filename, rdbSaveInfo *rsi) {
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp;
rio rdb;
int error = 0;
//格式化生成一个临时文件名
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
//以写模式,创建一个临时文件,准备写
fp = fopen(tmpfile,"w");
if (!fp) {
//创建失败的处理
char *cwdp = getcwd(cwd,MAXPATHLEN);
return C_ERR;
}
//初始化rdb的文件rio对象,因为要写到文件里,所以都是文件操作
rioInitWithFile(&rdb,fp);
if (server.rdb_save_incremental_fsync)
//设置缓冲区32mb
rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
//将所有的db写入文件
if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) {
errno = error;
goto werr;
}
/**
* 1, 刷新缓冲区
* 2,刷盘
* 3,释放文件资源
*/
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
//将临时文件重命名为rd的名称
if (rename(tmpfile,filename) == -1) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
//释放临时文件
unlink(tmpfile);
return C_ERR;
}
//记录log
serverLog(LL_NOTICE,"DB saved on disk");
//结束状态
server.dirty = 0;
//记录执行完成的时间
server.lastsave = time(NULL);
//记录状态为成功
server.lastbgsave_status = C_OK;
return C_OK;
werr:
fclose(fp);
unlink(tmpfile);
return C_ERR;
}在这里还有一个核心方法
/**
* 将db生成的rdb写入到指定的 I/O通道中。这个通道可以是磁盘IO,也可以是网络,也可以是内存
* @param rdb 指定的rdb格式和 io通道
* @param error
* @param flags
* @param rsi
* @return
*/
int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
int j;
uint64_t cksum;
size_t processed = 0;
//校验和
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
//前9个字节为rdb的魔数,用于标识rdb的情况,恢复的时候,能不能用,可以根据这个判断,java是0xCAFEBABE
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
// 写入一些别的信息
if (rdbSaveInfoAuxFields(rdb,flags,rsi) == -1) goto werr;
//用了哪些模块也写入进来了
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr;
//遍历所有的db,写入
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
//当前db的全局hash表
dict *d = db->dict;
if (dictSize(d) == 0) continue;
//获取hash表的迭代器
di = dictGetSafeIterator(d);
/* Write the SELECT DB opcode */
//写入db的操作码 254 ,一个字节
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
//保存数据库的序号
if (rdbSaveLen(rdb,j) == -1) goto werr;
/**
* 写入db和expires的大小
*/
uint64_t db_size, expires_size;
db_size = dictSize(db->dict);
expires_size = dictSize(db->expires);
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
//迭代全局hash表,一个个的获取数据,写入
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
initStaticStringObject(key,keystr);
expire = getExpire(db,&key);
//将key,val 和过期时间一起写入,这里会根据数据类型,解析数据,将这些标识 key val都写入到rdb中
if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
if (flags & RDB_SAVE_AOF_PREAMBLE &&
rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES)
{
processed = rdb->processed_bytes;
aofReadDiffFromParent();
}
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
if (rsi && dictSize(server.lua_scripts)) {
di = dictGetIterator(server.lua_scripts);
while((de = dictNext(di)) != NULL) {
robj *body = dictGetVal(de);
if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1)
goto werr;
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
//写完db后,写入一个结束标识
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;
/* EOF opcode */
//写入文件结束标识
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
//CRC64 校验,不支持CRC64直接写0
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
werr:
if (error) *error = errno;
if (di) dictReleaseIterator(di);
return C_ERR;
}在这里会把文件头(魔数)一些基本信息先写入文件,然后才会将数据一个个的获取到写入。
整个的文件格式如下:

看下写入rdbSaveKeyValuePair,具体的拆解就不说了
/**
* 保存key val 键值对 到磁盘
* 先获取过期策略,根据不同的过期策略计算最后的到期时间
* - 写到期时间
* - 写val的类型
* - 写key
* - 写val
* @param rdb rdb文件
* @param key
* @param val
* @param expiretime
* @return
*/
int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) {
int savelru = server.maxmemory_policy & MAXMEMORY_FLAG_LRU;
int savelfu = server.maxmemory_policy & MAXMEMORY_FLAG_LFU;
//写入到期时间
if (expiretime != -1) {
if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1;
if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1;
}
//写入LRU的过期时间,通过RDB_OPCODE_IDLE标识识别是LRU
if (savelru) {
//计算一次空闲时间
uint64_t idletime = estimateObjectIdleTime(val);
idletime /= 1000; /* Using seconds is enough and requires less space.*/
if (rdbSaveType(rdb,RDB_OPCODE_IDLE) == -1) return -1;
//将空闲时间写入
if (rdbSaveLen(rdb,idletime) == -1) return -1;
}
//写入LFU的信息,通过RDB_OPCODE_FREQ标识识别
if (savelfu) {
uint8_t buf[1];
//写入之前还得再衰减下
buf[0] = LFUDecrAndReturn(val);
if (rdbSaveType(rdb,RDB_OPCODE_FREQ) == -1) return -1;
if (rdbWriteRaw(rdb,buf,1) == -1) return -1;
}
/* Save type, key, value */
//写入数据类型标识(通过val的redisObject获取)
if (rdbSaveObjectType(rdb,val) == -1) return -1;
//写入key的值(最终转换为字符串)
if (rdbSaveStringObject(rdb,key) == -1) return -1;
//根据val类型组装不同写入值(list,hash,set这些都会一条条的解析出来)
if (rdbSaveObject(rdb,val,key) == -1) return -1;
return 1;
}不落盘的rdb
在以下的代码里
int startBgsaveForReplication(int mincapa) {
if (rsiptr) {
if (socket_target)
//不落盘进行传输(直接写到网络流里)
retval = rdbSaveToSlavesSockets(rsiptr);
else
//落入磁盘进行rdb
retval = rdbSaveBackground(server.rdb_filename,rsiptr);
}
}这里的逻辑主要是主从复制使用。等到后面再讲。
serverCron中的调用
我们看下周期性任务serverCron是如何调用的。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
//这段代码下篇再讲
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&server.aof_rewrite_scheduled){
//aof重写
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||ldbPendingChildren()){
int statloc;
pid_t pid;
/**
* 获取终止的进程id
* statloc: 保存着子进程退出时的一些状态,它是一个指向int类型的指针,设置为null,直接kill掉子进程
* options:选项
* WNOHANG 如果没有结束的子进程,马上返回,不等待
* WUNTRACED 如果子进程进入暂停执行状态,则马上返回,不理会结束状态
* 也可以WNOHANG | WUNTRACED 没有任何已结束了的子进程或子进程进入暂停执行的状态,则马上返回不等待
*/
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
//获取子进程的结束代码
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
//如果子进程因为信号而结束,获取信号代码
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
if (pid == -1) {
//日志输出
} else if (pid == server.rdb_child_pid) {
//是rdb子进程,说明rdb执行完了,执行后续的事件
backgroundSaveDoneHandler(exitcode,bysignal);
//不是因为信号中断的,接收子进程信息
if (!bysignal && exitcode == 0) receiveChildInfo();
} else if (pid == server.aof_child_pid) {
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else {
//无法识别的子进程,,直接移除
if (!ldbRemoveChild(pid)) {
}
}
updateDictResizePolicy();
//关闭子进程管道
closeChildInfoPipe();
}
} else {
//这一块就是处理配置文件中save 900 1的地方
for (j = 0; j < server.saveparamslen; j++) {
//获取配置
struct saveparam *sp = server.saveparams+j;
/**
* 判断是否达到了执行rbd的条件
*/
if (server.dirty >= sp->changes &&server.unixtime-server.lastsave > sp->seconds &&(server.unixtime-server.lastbgsave_try >CONFIG_BGSAVE_RETRY_DELAY ||server.lastbgsave_status == C_OK)) {
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
//后台rdb,这里调到了rdbSaveBackground
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
if (server.aof_state == AOF_ON &&server.rdb_child_pid == -1 &&server.aof_child_pid == -1 &&server.aof_rewrite_perc &&server.aof_current_size > server.aof_rewrite_min_size){
long long base = server.aof_rewrite_base_size ?server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
//触发aof重写(配置文件auto-aof-rewrite-min-size 64mb)
rewriteAppendOnlyFileBackground();
}
}
}
}在这里周期性任务里,获取到之前的fork的子进程的执行情况,然后做分发处理。
- 如果有子进程,并且有结果了,会根据子进程的类型做分发,去rdb或aof的后续处理
- 如果没有子进程,先去看有没有达到rdb的触发条件,达到,触发执行,未达到看下是否执行aof重写
- rdb和aof同时只能有一个在执行
在以下的代码中读取子进程写回的信息,关闭子进程的管道,将管道的值置为-1
/**
* 通过管道读取子进程的返回的信息
*/
void receiveChildInfo(void) {
if (server.child_info_pipe[0] == -1) return;
ssize_t wlen = sizeof(server.child_info_data);
if (read(server.child_info_pipe[0],&server.child_info_data,wlen) == wlen &&
server.child_info_data.magic == CHILD_INFO_MAGIC)
{
//rdb的处理
if (server.child_info_data.process_type == CHILD_INFO_TYPE_RDB) {
//获取子进程读写数据的大小
server.stat_rdb_cow_bytes = server.child_info_data.cow_size;
//aof的处理
} else if (server.child_info_data.process_type == CHILD_INFO_TYPE_AOF) {
server.stat_aof_cow_bytes = server.child_info_data.cow_size;
}
}
}
/**
* 关闭子进程管道,并将管道的fd值置为-1
*/
void closeChildInfoPipe(void) {
if (server.child_info_pipe[0] != -1 ||
server.child_info_pipe[1] != -1)
{
//关闭管道
close(server.child_info_pipe[0]);
close(server.child_info_pipe[1]);
//并将值置为-1
server.child_info_pipe[0] = -1;
server.child_info_pipe[1] = -1;
}
}/**
* 子进程执行完rdb后的处理
* @param exitcode 获取子进程的结束代码,exitcode=0 表示rdb成功,1表示失败
* @param bysignal 子进程信号中断代码,如果非0 ,表示被信号中断
*/
void backgroundSaveDoneHandler(int exitcode, int bysignal) {
switch(server.rdb_child_type) {
case RDB_CHILD_TYPE_DISK:
backgroundSaveDoneHandlerDisk(exitcode,bysignal);
break;
case RDB_CHILD_TYPE_SOCKET:
backgroundSaveDoneHandlerSocket(exitcode,bysignal);
break;
default:
serverPanic("Unknown RDB child type.");
break;
}
}在这里根据rdb子进程的类型,处理主从同步的逻辑,这块下下次再讲。
整体分析下来,对这块应该有个清晰的认识。
- rdb会丢数据? 根据配置,rdb备份对数据是有一定的延迟,为了redis性能,不能太频繁,也不能间隔太短;这中间各种异常会导致rdb数据丢失;
- rdb写入的到期时间,可能在恢复的时候,已经过期
在rdbSaveRio方法的的时候,有个参数是rio,这块我们重点看下这个。
在rio.h中定义了结构体
/**
* rio结构体,可以认为是指定了rdb的格式提供标准的读写io的操作方法,
*/
struct _rio {
//函数指针
//读函数指针
size_t (*read)(struct _rio *, void *buf, size_t len);
//写函数指针
size_t (*write)(struct _rio *, const void *buf, size_t len);
//指针移动函数的指针
off_t (*tell)(struct _rio *);
// 刷入函数的指针
int (*flush)(struct _rio *);
//校验和计算方法
void (*update_cksum)(struct _rio *, const void *buf, size_t len);
/* The current checksum */
//校验和
uint64_t cksum;
/* number of bytes read or written */
//已读取或写入的字符串
size_t processed_bytes;
/* maximum single read or write chunk size */
//每次最多处理的字符数
size_t max_processing_chunk;
/* Backend-specific vars. */
//io共用体(可标识为内存,文件,网络)
union {
/* In-memory buffer target. */
//内存buffer的
struct {
sds ptr;
off_t pos;
} buffer;
/* Stdio file pointer target. */
//文件
struct {
FILE *fp;
off_t buffered; /* Bytes written since last fsync. */
off_t autosync; /* fsync after 'autosync' bytes written. */
} file;
/* Multiple FDs target (used to write to N sockets). */
//socke的
struct {
//文件描述符,也是socket的 fd
int *fds; /* File descriptors. */
int *state; /* Error state of each fd. 0 (if ok) or errno. */
int numfds;
off_t pos;
sds buf;
} fdset;
} io;
};
typedef struct _rio rio;
在rio.c中
/**
* const 规定一个一个变量在初始化之后不能改变
* 文件的rio的初始化
* 适用于文件的rio对象,写文件的时候使用
*/
static const rio rioFileIO = {
rioFileRead, //文件读
rioFileWrite,//文件写
rioFileTell,//文件指针移动
rioFileFlush,//刷入文件
NULL, /* update_checksum */
0, /* current checksum */
0, /* bytes read or written */
0, /* read/write chunk size */
{ { NULL, 0 } } /* union for io-specific vars */
}
/**
* Buffer的rio初始化
* 适用于内存缓存的rio对象,从文件加载rdb到内存的时候,使用
*/
static const rio rioBufferIO = {
rioBufferRead, //Buffer的读
rioBufferWrite,//Buffer的写
rioBufferTell, //buffer的指针移动
rioBufferFlush,// 刷入buffer
NULL, /* update_checksum */
0, /* current checksum */
0, /* bytes read or written */
0, /* read/write chunk size */
{ { NULL, 0 } } /* union for io-specific vars */
};
/**
* 网络操作的rio初始化
* 适用于网络的rio对象,写文件的时候使用
*/
static const rio rioFdsetIO = {
rioFdsetRead, //网络读
rioFdsetWrite, //网络写
rioFdsetTell, // fd的指针移动
rioFdsetFlush,//刷入网络
NULL, /* update_checksum */
0, /* current checksum */
0, /* bytes read or written */
0, /* read/write chunk size */
{ { NULL, 0 } } /* union for io-specific vars */
};最终在rdb里操作的都是rio,看到这,是不是和java里的接口很像?
- c中通过指针指向了具体的函数(java中直接用的标识符)
- c通过初始化为各个指针赋值了具体的执行方法(java通过实现接口)
- rioFileIO、rioBufferIO、rioFdsetIO可以理解为rio的具体实现类
rdb 加载
- 在main函数里,当redis启动的时候会加载rdb(如果有的话)
int main(int argc, char **argv) {
InitServerLast();
loadDataFromDisk();
}
void loadDataFromDisk(void) {
rdbSaveInfo rsi = RDB_SAVE_INFO_INIT;
if (rdbLoad(server.rdb_filename,&rsi) == C_OK) {
}
}
在rdb.c中
/**
* 从文件加载rdb信息到并解析到内存
* @param filename
* @param rsi
* @return
*/
int rdbLoad(char *filename, rdbSaveInfo *rsi) {
FILE *fp;
rio rdb;
int retval;
//读取rdb文件
if ((fp = fopen(filename,"r")) == NULL) return C_ERR;
// 初始化加载配置
startLoading(fp);
//初始化文件rio
rioInitWithFile(&rdb,fp);
//反向解析rdb文件
retval = rdbLoadRio(&rdb,rsi,0);
fclose(fp);
stopLoading();
return retval;
} redis系列文章
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了
redis源码阅读五-为什么大量过期key会阻塞redis?
本文是Redis源码剖析系列博文,有想深入学习Redis的同学,欢迎star和关注;
Redis中文注解版:https://github.com/yxkong/redis/tree/5.0
如果觉得本文对你有用,欢迎一键三连;
同时可以关注微信公众号5ycode获取第一时间的更新哦;


文章评论