
背景 之前学习mysql的时候,了解了到了页,段的概念,页的结构是什么,都简单的了解下了,毕竟都是纸面看到的,也没有深入源码了解。总觉的悬在上面,直接通过数据库文件反编译也比较麻烦。媳妇介绍了一个工具innodb_ruby, 说它可以扒mysql数据的结构。这几天扒拉了下,蛮好用的,好多知识也和之前的对上了。 我的mysql的配置文件如下(本地开发单机环境,没做什么优化,也没开启binlog): [root@localhost data]# cat /etc/my.cnf [client] #客户端默认连接字集集,…
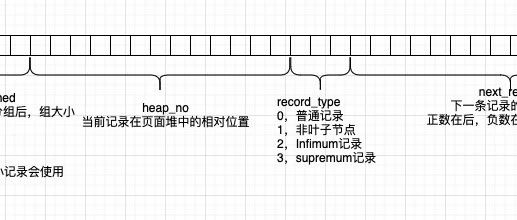
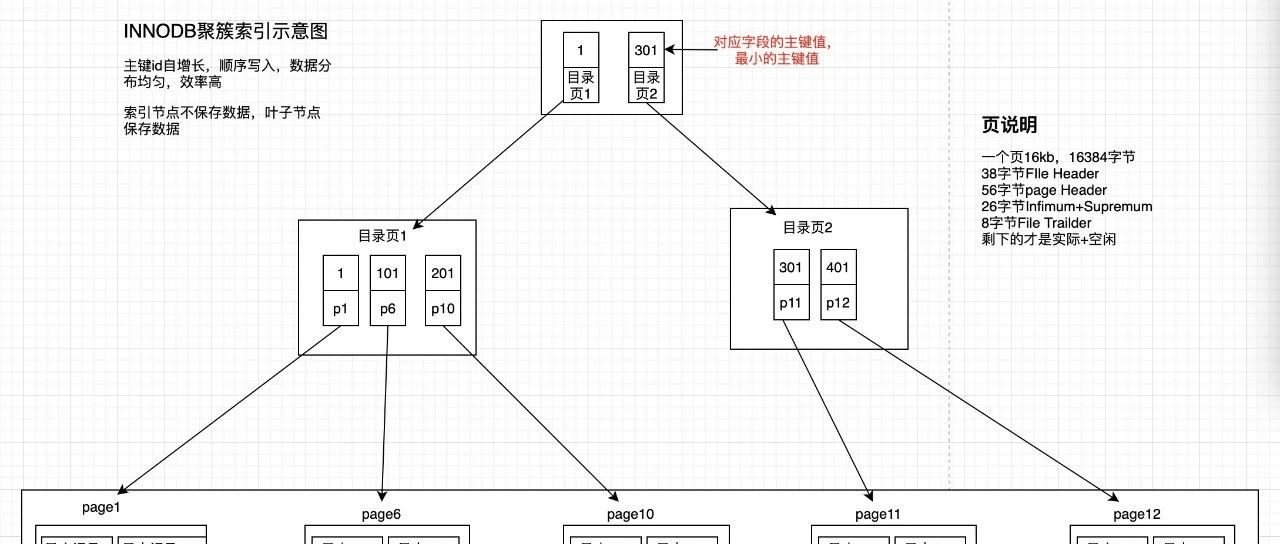
InnoDB,是MySQL的数据库引擎之一,现为MySQL的默认存储引擎,为MySQL AB发布binary的标准之一。 InnoDB存储结构 以页为单位来管理存储空间; 以页作为磁盘和内存交互的基本单位; 默认页大小为16kb(所以最少一次从磁盘读取16kb的内容),可以通过innodb_page_size 修改页的大小(在初始化时指定 mysqld --initialize); 不同的行格式在磁盘上的存放形式也不同; mysql规定一页中最少存储2行数据 页中需要占用的额外空间需要132字节 compact 行…
5ycode 被管理耽误的架构师。工作、学习过程中的知识总结与分享,jvm,多线程,架构设计,经验分享等。 30篇原创内容 公众号 接之前的事务系列 mysql事务-innodb中的redolog详解 innodb中的undolog 详解 mysql事务-MVCC 通过前面几篇文章,我们知道,并发产生的事务,基本上会有写-写,读-写或写-读,也是由于隔离级别的不同,可能会导致脏读、幻读等问题。 在这篇(mysql事务-MVCC)文章中,我们了解到读操作通过多版本并发控制(MVCC)来解决不一致的问题。 写操作可以通…
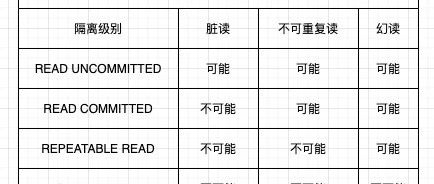
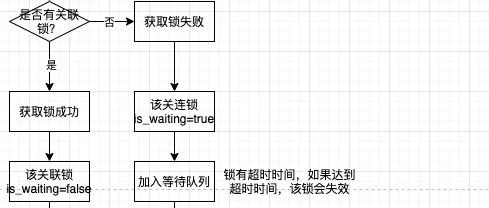
mysql事务-innodb中的redolog详解 innodb中的undolog 详解 什么是MVCC? 使用READ COMMITTD、REPEATABLE READ 这两种隔离级别的事务执行select操作时,我们通过记录的版本链来控制事务访问相同记录时的行为,这种机制称为多版本并发控制(Multi-Version Concurrency Control). 目的:是为了提升并发访问的性能。 并发的事务在运行过程中会出现一些可能引发一致性问题的现象 脏写(dirty write):一个事务修改了另…
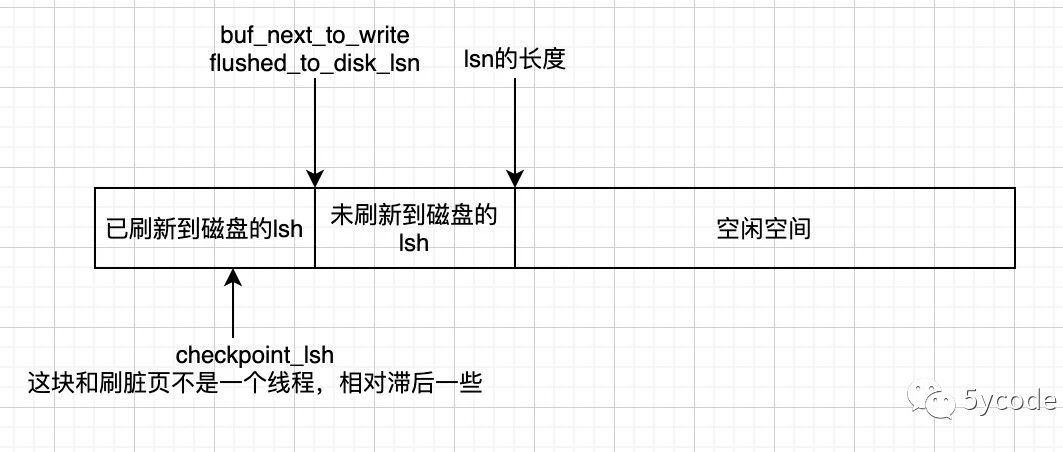
redo 日志 什么是redo日志?是为了在系统因崩溃而重启时恢复崩溃前的状态而产生的概念,mysql在运行过程中修改数据时由innodb引擎产生的(某个表空间第n号页面中偏移量为m处的值由x更新为y)记录日志,用于保证持久性; redo log从 log buffer 刷入磁盘的时机: log buffer 空间不足; 事务提交 (这也是为啥事务会影响性能的点之一); 定时刷盘(每秒),通过flush链表 服务正常停止; 做checkpoint时; innodb_flush_log_at_trx_co…
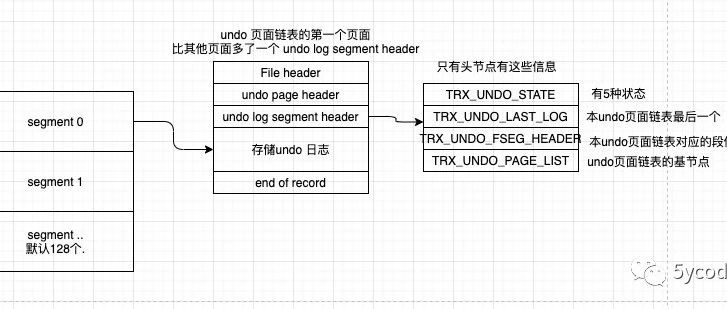
5ycode 被管理耽误的架构师。工作、学习过程中的知识总结与分享,jvm,多线程,架构设计,经验分享等。 28篇原创内容 公众号 mysql事务-innodb中的redolog详解 继上一篇redo log之后详解下 undo log. 什么是undolog? 是为了保证数据库的原子性,增加的增删改逻辑记录日志。 undo log是逻辑日志 redo log记录的是物理日志 有两个作用: 事务回滚 多个行版本控制(MVCC) undo log的存储方式 undo 日志链表 一共有四种undo日志链表,在生成und…

背景:在博客迁移过程,由于误操作原来的mysql无法启动,只能通过新建一个mysql,然后清空data目录,将原来的data都拷贝过去。 启动后登录没问题,读取也没问题,就是无法写入,出现了Table‘xxx’is read only。 我这是因为迁移后修改my.cnf文件多加了一个配置导致 [mysqld]log-error = /app/data/mysql/logs/error.logpid-file = /app/data/mysql/mysql.pidport = 3306socket = /app/da…
今天测试在验证的时候,测试反馈工单后台查看数据特别慢,慢到数据无法展示。那就看下呗。看了下有慢sql。 本着对生产敬畏的心态,转移到测试环境进行验证。测试数据不够,自己造呗。工单表具备以下特征: 数据字段多,索引也多; 随着数据的流转,数据一直在更新;以下数据是参考测试表结构的模拟; -- 创建表,多加了几个字段为了占用空间填充CREATE TABLE `t_loan_order` ( `app_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '工单ID', `cust…
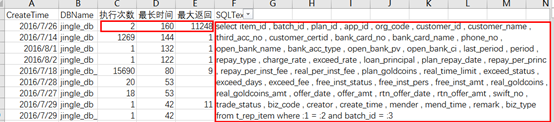
根据导出的近半个月的慢sql和相关表索引的排查,大致有以下几种类型的问题: 一)索引相关 1)未建立索引 后已加 建议增加cutomer_id的索引 2)索引未充分利用 由于mysql检索是从左到右,建议查询时,将主索引放第一位;若时查询条件较多,建议创建组合索引 3)两张表关联字段类型不一致导致索引失效 二)语句相关 1)数据量大的表查询返回数量过大 全量查询返回数据行数过多: 条件区域过大,返回数据过多 …

有一个需求,一张表中有1亿条数据,现在要分表处理。数据分离是个麻烦事。以下为本人的解决方案。效率还行。 -- 创建测试表 CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY K…
