Java在JDK7之后加入了并行计算的框架Fork/Join,可以解决我们系统中大数据计算的性能问题。Fork/Join采用的是分治法,Fork是将一个大任务拆分成若干个子任务,子任务分别去计算,而Join是获取到子任务的计算结果,然后合并,这个是递归的过程。子任务被分配到不同的核上执行时,效率最高。
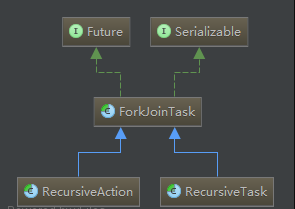
Fork/Join框架的核心类是ForkJoinPool,它能够接收一个ForkJoinTask,并得到计算结果。ForkJoinTask有两个子类,RecursiveTask(有返回值)和RecursiveAction(无返回结果),我们自己定义任务时,只需选择这两个类继承即可。类图如下:

下面分享一个案例:
package com.yxkong.demo.forkJoin;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* RecursiveTask 并行计算,同步有返回值
* ForkJoin框架处理的任务基本都能使用递归处理,比如求斐波那契数列等,但递归算法的缺陷是:
* 一只会只用单线程处理,
* 二是递归次数过多时会导致堆栈溢出;
* ForkJoin解决了这两个问题,使用多线程并发处理,充分利用计算资源来提高效率,同时避免堆栈溢出发生。
* 当然像求斐波那契数列这种小问题直接使用线性算法搞定可能更简单,实际应用中完全没必要使用ForkJoin框架,所以ForkJoin是核弹,是用来对付大家伙的,比如超大数组排序。
* 最佳应用场景:多核、多内存、可以分割计算再合并的计算密集型任务。
* @author ducongcong
* @date 2017年4月14日
*/
public class RecursiveTaskTest extends RecursiveTask {
/**
*
*/
private static final long serialVersionUID = 6253771003381008573L;
//分片阈值
public static final int threshold = 100;
private int start;
private int end;
public RecursiveTaskTest(int start,int end) {
this.start = start;
this.end = end;
}
/**
* fork()方法:将任务放入队列并安排异步执行,一个任务应该只调用一次fork()函数,除非已经执行完毕并重新初始化。
* tryUnfork()方法:尝试把任务从队列中拿出单独处理,但不一定成功。
* join()方法:等待计算完成并返回计算结果。
* isCompletedAbnormally()方法:用于判断任务计算是否发生异常。
*/
@Override
protected Integer compute() {
int total = 0;
String threadName = Thread.currentThread().getName();
//小于阈值直接执行
if(end-start <= threshold){
for(int i= start;i<end;i++){
total+=i;
}
System.err.println(threadName+" total:"+total);
}else{
//递归拆解任务,拆解到阈值范围内(每个work分配指定计算的数量)
int middle = (start+end) / 2;
RecursiveTaskTest leftTask = new RecursiveTaskTest(start, middle);
RecursiveTaskTest rightTask = new RecursiveTaskTest(middle, end);
//正确写法
invokeAll(leftTask, rightTask);
// 执行子任务
//fork()方法:将任务放入队列并安排异步执行,一个任务应该只调用一次fork()函数,除非已经执行完毕并重新初始化。
// 错误写法
// leftTask.fork();
// rightTask.fork();
//等待计算完成并返回计算结果。
int left = leftTask.join();
int right = rightTask.join();
// System.err.println(String.format("split %d~%d ==> %d~%d, %d~%d", start, end, start, middle, middle, end));
total= left+right;
System.err.println(threadName+" left+right:"+total);
}
return total;
}
static int total(int start,int end){
int total = 0;
for(int i=start;i<end;i++){
total +=i;
}
return total;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
long s = System.currentTimeMillis();
RecursiveTaskTest task = new RecursiveTaskTest(1, 10000);
ForkJoinTask submit = forkJoinPool.submit(task);
try {
System.err.println(Thread.currentThread().getName()+" result: "+ submit.get() +" 耗时:" +(System.currentTimeMillis()-s));
} catch (Exception e) {
e.printStackTrace();
}
long s1 = System.currentTimeMillis();
int total = total(1,10000);
forkJoinPool.shutdown();
System.err.println("total:"+total+" 耗时:"+(System.currentTimeMillis()-s1));
}
}
使用错误写法时,输出:
ForkJoinPool-1-worker-14 total:417339
ForkJoinPool-1-worker-39 total:112671
ForkJoinPool-1-worker-33 total:118755
ForkJoinPool-1-worker-46 total:563589
ForkJoinPool-1-worker-43 total:551421
ForkJoinPool-1-worker-11 total:557505
ForkJoinPool-1-worker-47 total:715923
ForkJoinPool-1-worker-33 total:155337
ForkJoinPool-1-worker-45 total:722007
ForkJoinPool-1-worker-45 total:737465
....
ForkJoinPool-1-worker-25 total:222339
main result: 49995000 耗时:30
total:49995000 耗时:0
使用正确写法时,输出:
ForkJoinPool-1-worker-1 total:3081
......
ForkJoinPool-1-worker-2 total:589340
ForkJoinPool-1-worker-1 total:167505
ForkJoinPool-1-worker-4 total:575757
ForkJoinPool-1-worker-1 total:173589
ForkJoinPool-1-worker-1 total:179673
ForkJoinPool-1-worker-3 total:557505
ForkJoinPool-1-worker-1 total:194340
ForkJoinPool-1-worker-4 total:185757
main result: 49995000 耗时:4
total:49995000 耗时:0
并行计算的任务越多耗时越明显,为什么会出现这样的情况呢?
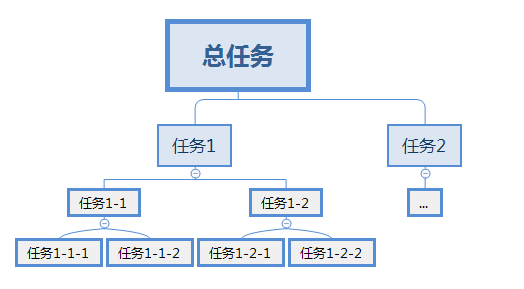
使用fork/join后,拆分的任务应该是每个独立执行,执行完以后合并到总任务上,错误的写法导致每个任务执行子任务都需要等待它下面的子任务执行完才会执行自己的任务。导致拆分的越多就越慢。
JDK用来执行Fork/Join任务的工作线程池大小等于CPU核心数。在一个4核CPU上,最多可以同时执行4个子任务。对400个元素的数组求和,执行时间应该为1秒。但是,换成上面的代码,执行时间却是两秒。
这是因为执行compute()方法的线程本身也是一个Worker线程,当对两个子任务调用fork()时,这个Worker线程就会把任务分配给另外两个Worker,但是它自己却停下来等待不干活了!这样就白白浪费了Fork/Join线程池中的一个Worker线程,导致了4个子任务至少需要7个线程才能并发执行。
打个比方,假设一个酒店有400个房间,一共有4名清洁工,每个工人每天可以打扫100个房间,这样,4个工人满负荷工作时,400个房间全部打扫完正好需要1天。
Fork/Join的工作模式就像这样:首先,工人甲被分配了400个房间的任务,他一看任务太多了自己一个人不行,所以先把400个房间拆成两个200,然后叫来乙,把其中一个200分给乙。紧接着,甲和乙再发现200也是个大任务,于是甲继续把200分成两个100,并把其中一个100分给丙,类似的,乙会把其中一个100分给丁,这样,最终4个人每人分到100个房间,并发执行正好是1天。
如果换一种写法:
// 分别对子任务调用fork():
leftTask.fork();
rightTask.fork();
这个任务就分!错!了!
比如甲把400分成两个200后,这种写法相当于甲把一个200分给乙,把另一个200分给丙,然后,甲成了监工,不干活,等乙和丙干完了他直接汇报工作。乙和丙在把200分拆成两个100的过程中,他俩又成了监工,这样,本来只需要4个工人的活,现在需要7个工人才能1天内完成,其中有3个是不干活的。
其实,我们查看JDK的invokeAll()方法的源码就可以发现,invokeAll的N个任务中,其中N-1个任务会使用fork()交给其它线程执行,但是,它还会留一个任务自己执行,这样,就充分利用了线程池,保证没有空闲的不干活的线程。


文章评论