
接之前的事务系列
通过前面几篇文章,我们知道,并发产生的事务,基本上会有写-写,读-写或写-读,也是由于隔离级别的不同,可能会导致脏读、幻读等问题。
在这篇(mysql事务-MVCC)文章中,我们了解到读操作通过多版本并发控制(MVCC)来解决不一致的问题。
写操作可以通过加锁来解决。
先简单的梳理下并发时,更新记录时的加锁机制。
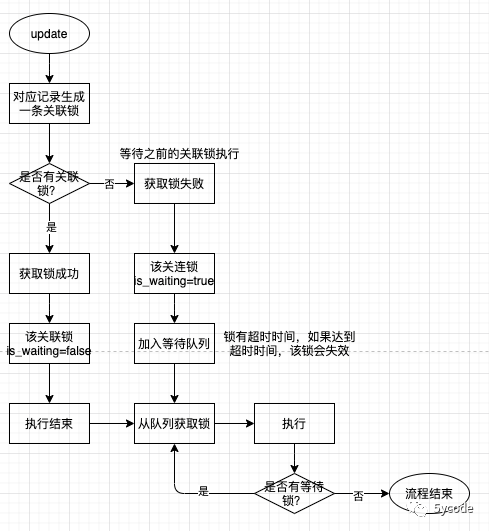
到此,我们挂起。
加锁 带来的问题
-
脏读
-
脏页:缓冲池已修改,还未刷新到磁盘;
-
脏数据 事务未commit时;
-
脏读 读到未提交的数据
-
不可重复读,一个事务内多次读取同一数据集合,另一个事务提交了
-
丢失更新,电商购物,用户取消和发货同时进行,发货未看最新状态
-
阻塞 锁释放过慢会导致
共享锁(Shared Lock) :
-
InnoDB存储引擎;
-
读锁(S锁);
-
其他事务可以读,但不可以写;
-
共享,别人获取了S锁,他人是可以再获取S锁,但是不能再获取该记录的X锁
-
获取S锁 select ... lock in share mode;
独占锁(Exclusive Lock)
-
InnoDB存储引擎;
-
写锁(X锁);
-
排他,其他事务不可以读,也不可以写;
-
对于update、delete、insert语句,InnoDB自动给数据集加X锁;
-
对于select语句获取x锁, select ... for update,这样只有自己才能更新数据,其他事务无法更新;
-
优先级比读锁高;
元数据锁(Metadata lock)
msyql使用DML来管理对数据库对象的并发访问,并确保数据一致性。在5.5.3以前,当一个会话在主库执行DML操作还没有提交时,另一个会话对同一个对象执行了DDL操作,如DROP,mysql的binglog是基于事务提交的先后顺序进行记录的,因此在slave上就出现了先drop,再insert的情况。
解决以下问题:
-
事务隔离问题,dml操作后,数据结果不一致,无法满足重复读的需求;
-
数据复制问题(binlog同步)
常见DML锁场景:
-
当前有执行DML操作(DML未执行完成)时,执行DDL操作;
-
当前有对标长时间查询或使用mysqldump、mysqlpump时,执行DDL会堵住;
-
显示或者隐式开启事务后未提交或回滚,比如查询完成后未提交或者回滚,DDL会被堵住;
-
表上有失败的查询事务,比如查询不存在的列,语句失败返回,但是事务没有提交,此时DDL仍然会被堵住;
悲观锁
假定会发生冲突,屏蔽一些可能违反数据完整性的操作。
-
每次拿数据,都会认为别人会修改;
-
所以每次拿数据都会上锁(行锁、表锁等)
乐观锁
假设不会发生并发冲突,在提交操作时检查是否违反了数据完整性。
-
不能解决脏读(通过隔离级别可以);
-
每次拿数据,认为别人不会改,所以不上锁;
-
更新时判断一下在此期间别人有没有更新这个数据;
-
适用于多读的应用;
锁比较
表锁
-
开销小,加锁快;
-
不会出现死锁
-
力度大,并发冲突概率高;
-
并发度低;
-
适用于读多,写少的场景
行锁
-
开销大,加锁慢;
-
锁逐步获取,有死锁的可能性;
-
力度小、并发冲突小;
-
并发度高;
-
适用于并发更新量少的场景;
页面锁
-
BDB存储引擎
-
介于表锁和行锁之间
-
有出现死锁的可能性;
-
并发度一般;
表锁
表共享锁(S锁)
-
MyISAM、MEMORY、MERGE 这些存储引擎
-
读锁(S锁)
-
其他事务可以读,但不可以写;
-
共享
-
low-priority-updates 参数设置锁优先级
-
自动加锁
表独占锁(X锁)
-
MyISAM、MEMORY、MERGE 这些存储引擎
-
写锁(X锁)
-
排他
-
开销小,加锁快
-
自动加锁
意向共享锁(IS)
-
InnoDB存储引擎
-
给数据行加共享锁,必须先获取该锁
-
隐式锁(InnoDB会根据隔离级别帮我们做,不需要我们关心)
意向独占锁(IX)
-
InnoDB存储引擎
-
给数据行加独占锁,必须先获取该锁
-
隐式锁(InnoDB会根据隔离级别帮我们做,不需要我们关心)
行锁
-
InnoDB给索引项加锁实现行锁(必须用索引查);
-
执行计划里用了索引才算(有时候索引会不起作用);
间隙锁(GAP)
-
条件范围检索数据,对这个范围进行加锁,可能有些数据不连贯,产生了间隙,这些间隙也会加锁;
-
适用于批量插入,锁定一段空间,主键自增;
-
防止幻读;
-
满足恢复和复制的需要;
-
恢复和复制都是要保证顺序的,在这个事务没有完成之前,别的事务是不能动的;
next-key Lock
既能锁住当前记录,又能阻止其他是在在该记录之前的间隙中插入记录。官方名称为 LOCK_ORDINARY 可以理解为一个行锁+一个间隙锁组成。
InnoDB锁的内存结构

type_mode(32 bit)
-
lock_mode (低4位) 锁模式
-
LOCK_LS: 0 意向共享锁
-
LOCK_IX: 1 意向独占锁
-
LOCK_S: 2 共享锁
-
LOCK_X: 3 独占锁
-
LOCK_AUTO_INC: 4 AUTO_INC锁
-
lock_type (5~8位) 锁类型
-
LOCK_TABLE: 16 占第5bit,标记为1,表示表级锁
-
LOCK_REC: 32 占第6bit,标记为1,表示行级锁
-
rec_lock_type 行锁的具体类型
-
LOCK_ORDINARY: 0 表示next-key锁;
-
LOCK_GAP: 512 第10bit为1,表示gap锁;
-
LOCK_REC_NOT_GAP: 1024 第11bit为1
-
LOCK_INSERT_INTENTION: 2048 第12位bit为1, 表示插入意向锁;
-
LOCK_WAIT: 256 第9位bit为1,表示is_waiting为true获取锁失败,为0 表示is_waiting为false,获取锁成功
sql语句加锁分析
普通SELECT语句
在不同的隔离级别下,普通的select语句有不同的状态
-
在READ UNCOMMITTED隔离级别下, 不加锁,直接读最新版本,会出现脏读、幻读和不可重复读;
-
在READ COMMITTED 隔离级别下,不加锁,每次查询都会生成一个ReadView,避免了脏读,但没法避免幻读和不可重复读;
-
在REPEATABLE READ隔离级别下,不加锁,在第一次执行select时生成ReadView, 就避免了脏读、幻读和不可重复读;
带锁的SELECT语句
-
UPDATE ... 执行的条件 ,内部为select
-
DELETE ... 执行的条件,内部为select
-
select ... LOCK IN SHARE MODE;
-
select ... for update;
事务的一些查询辅助命令
mysql> select * from innodb_trx\Gmysql> select * from innodb_locks\Gmysql> select * from innodb_lock_waits\G
表结构
CREATE TABLE `t_demo` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`mobile` varchar(11) COLLATE utf8_bin NOT NULL COMMENT '手机号码',`name` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '昵称',`age` int(4) DEFAULT NULL COMMENT '年龄',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`),UNIQUE KEY `unq_idx_mobile` (`mobile`),KEY `idx_nick_name` (`name`),KEY `idx_create_mobile` (`mobile`,`create_time`)) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;INSERT INTO `test`.`t_demo` (`id`, `mobile`, `name`, `age`, `create_time`) VALUES (1, '13600000000', 'yxk', 21, '2021-06-29 12:21:02');INSERT INTO `test`.`t_demo` (`id`, `mobile`, `name`, `age`, `create_time`) VALUES (3, '15600000000', 'yxkong', 20, '2021-07-01 12:21:35');INSERT INTO `test`.`t_demo` (`id`, `mobile`, `name`, `age`, `create_time`) VALUES (5, '15500000000', 'yxk', 23, '2021-07-01 12:22:20');
RC= Read Committed
RR = Repeatable Read
S = Seralizable
select * from t_demo where id= 1;在Seralizable隔离级别下:
-
加读锁
-
MVCC并发控制降级为Lock_Base CC;
其他隔离级别:不加锁,使用mvcc并发控制;
delete from t_demo where id= 1;id是主键 RC和RR隔离级别 此sql只会在id=1这条记录上加X锁。
delete from t_demo where mobile= '13600000000';mobile是唯一索引 在RC和RR隔离级别下,这条sql会加两把X锁
-
对mobile为'13600000000'的unique索引加X锁;
-
对聚簇索引id=1的记录加X锁;
delete from t_demo where name= 'yxk';nike_name是二级非唯一索引 在RC隔离级别下
-
对name='yxk'的所有记录加X锁
-
以及对应的聚簇索引上加锁;
在RR隔离级别下:
-
定位到第一条满足条件的记录,对该记录加X锁;
-
加上GAP锁,然后加对应聚簇缩影的X锁;
-
返回
-
然后读取下一条,重复操作;
-
直到找到第一个不满足条件的记录,此时不需要加X锁,只需要GAP锁;
delete from t_demo where age= 20;在RC隔离级别下:
-
聚簇索引全表扫描过滤;
-
每条记录都会被加X锁,如果不满足条件会立即释放X锁;
在RR隔离级别下:
-
聚簇索引全表扫描;
-
所有记录都会加X锁;
-
稍有的GAP锁住;
-
杜绝所有的并发更新/删除/插入操作;
delete from t_demo where create_time>'2021-06-30 00:00:00' and create_time<'2021-07-04 00:00:00' and mobile='15500000000' and age=20;
在RR隔离级别下:
-
先根据create_time确定好范围
-
针对范围内的数据进行扫描;
-
范围内的数据都会加X锁
-
到看索引的第二条数据,会锁住id 1~3之间的间隙;
-
不符合条件,释放X锁;
-
依次往后执行


文章评论