前段时间给小伙伴分享redis,顺带又把redis撸了一遍了,对其源码,又有了比较深入的了解。(ps: 分享的文章再丰富下再放出来)。
数据结构
我们先看下redis 5.0的代码。本次讲解主要是zset中的跳表。压缩列表不做讲解
/**
* 跳跃表节点
*/
typedef struct zskiplistNode {
//member对象
sds ele;
//权重分值
double score;
//后退指针
struct zskiplistNode *backward;
//层级描述
struct zskiplistLevel {
//前进指针
struct zskiplistNode *forward;
//跨越节点的数量
unsigned long span;
} level[];
} zskiplistNode;
/**
* zset的数据结构跳跃表
*/
typedef struct zskiplist {
//头尾节点指针
struct zskiplistNode *header, *tail;
//节点数量
unsigned long length;
//最大层数
int level;
} zskiplist;
/**
* 跳表结构的zset
*/
typedef struct zset {
//kv形式,存储所有的member和对应的score
dict *dict;
//跳跃表
zskiplist *zsl;
} zset;zadd添加数据流程
我们从源码zadd看下zset命令(精简后的源码),在t_zset.c中
void zaddGenericCommand(client *c, int flags) {
//不存在,就创建
if (zobj == NULL) {
/**
* 根据redis的配置,如果有序集合不使用ziplist存储或者第一次插入元素的个数大于设置的ziplist最大长度,则使用跳表
*/
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)){
//这里创建了一个score为0,层级为64的元素为null的 头节点
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
//插入entry到hash表
dbAdd(c->db,key,zobj);
} else {//存在,校验类型,不是zset,报错
if (zobj->type != OBJ_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
//遍历所有的<element,score>
for (j = 0; j < elements; j++) {
double newscore;
score = scores[j];
int retflags = flags;
//获取元素数据的指针
ele = c->argv[scoreidx+1+j*2]->ptr;
//添加元素到zset,在zsetAdd 方法里进行了类型区分
int retval = zsetAdd(zobj, score, ele, &retflags, &newscore);
if (retval == 0) {
addReplyError(c,nanerr);
goto cleanup;
}
//根据操作类型计数
if (retflags & ZADD_ADDED) added++;
if (retflags & ZADD_UPDATED) updated++;
if (!(retflags & ZADD_NOP)) processed++;
score = newscore;
}
//计数
server.dirty += (added+updated);
}
/**
* zset添加元素
* @param zobj zset的存储结构
* @param score 添加的分值
* @param ele 元素对象
* @param flags
* @param newscore 添加成功后的分值
* @return
*/
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//存在先删后插
}else if (!xx) {
//超过配置长度,就将压缩链表转到了跳跃表
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value ||
!ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*flags |= ZADD_ADDED;
return 1;
}
}
}
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//zset 指针
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
//从zset的全局hash表中查找对应的key,找到说明已经存在,如果需要更新就操作,不需要就返回
de = dictFind(zs->dict,ele);
if (de != NULL) {
if (score != curscore) {
//这里先删除,然后重新插入,单线程保证了一致性,最后插入还是走的zslInsert
znode = zslUpdateScore(zs->zsl,curscore,ele,score);
//更新全局hash表里的权重分值
dictGetVal(de) = &znode->score; /* Update score ptr. */
*flags |= ZADD_UPDATED;
}
}else if (!xx) {
//将元素压缩成一个紧凑型的sds
ele = sdsdup(ele);
//插入元素
znode = zslInsert(zs->zsl,score,ele);
//将元素插入到对应的hash表中
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
*flags |= ZADD_ADDED;
if (newscore) *newscore = score;
return 1;
}
}
}通过源码:
在插入的元素的时候逻辑如下:
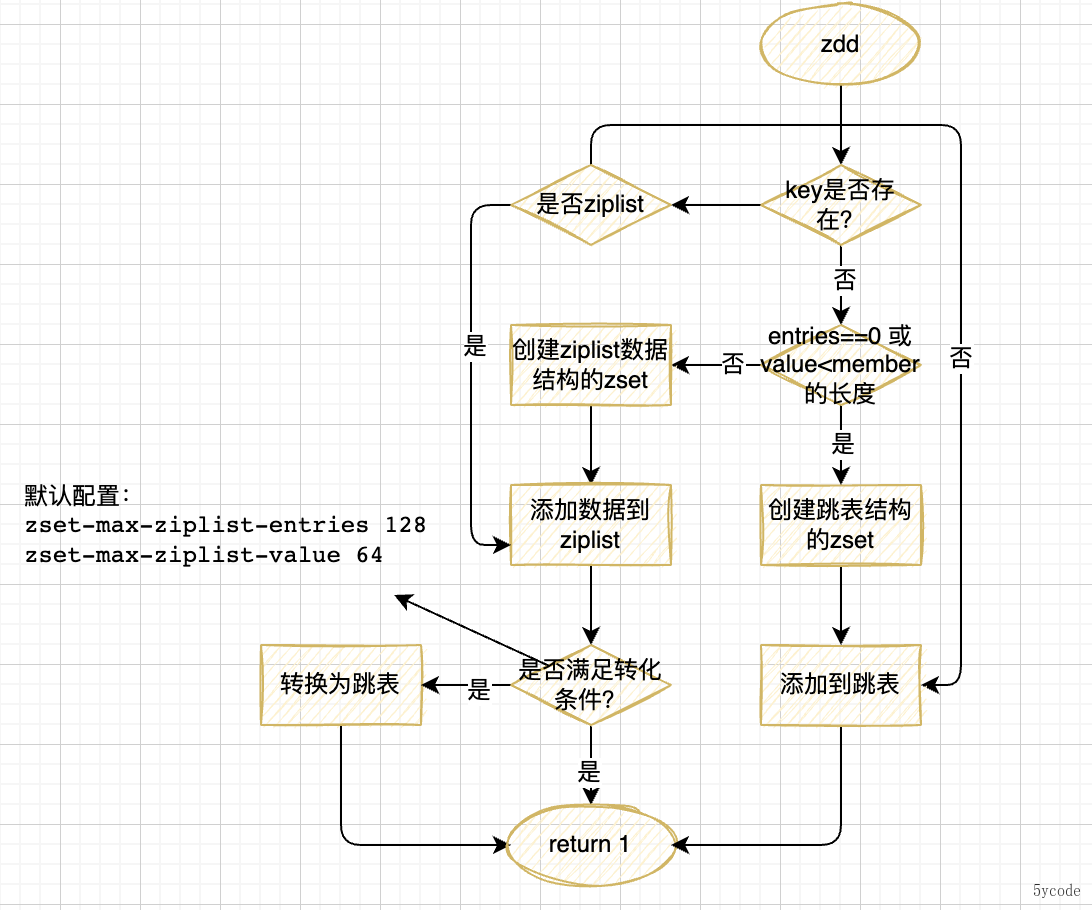
- 如果第一次为空,根据元素的个数创建zset的数据结构,默认是创建ziplist
- 当使用压缩链表ziplist的时候
跳跃表的创建与插入
我们重点看下跳跃表的操作
/**
* 创建一个跳跃表(具体实现)
*/
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
// header是一个权重分值为0,元素为NULL的对象
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
//新创建的跳跃表的header是一个64层级的空表
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
/**
* 跳表结构插入一条数据
* @param zsl 从zset上获取到跳跃表
* @param score 权重分值
* @param ele 元素
* @return
*/
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
/**
* update 保存对应层级小于插入权重分值的前一个节点,如果没有为header
* 新添加层级保存的是跳跃表的header指针
* x 表示zskiplistNode节点指针
*/
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
/**
* 每一层对应到update对应层级那个位置的跨度
*/
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
//最开始为头节点
x = zsl->header;
//逆序遍历当前的所有层级,找到新插入权重分值每一层左侧的数据
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
//最上层 rank为0,否则为i+1(相当于逆序了)
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
/**
* 前驱指针存在,
* 并且(当前指针对应的分值小于插入分值 或者(当前分值等于插入分值 并且现有元素和插入元素不相同))
* 比如当前权重分值为 20,跨度5,插入权重分值为30 ,或者 权重分值都为20,但是元素长度不相同(分值相同的话看元素长度大小,小的在前)
* 继续往下一个节点走,会记录下满足条件的跨度
* 通过这块,可以看到在zset里是根据分数权重,然后根据元素的长度大小升序排序
*/
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//将符合条件的层级跨度收集起来
rank[i] += x->level[i].span;
//链表往下走
x = x->level[i].forward;
}
//将每一层的要插入值的最近一个节点更新到update数组里
update[i] = x;
}
/**
* 随机层级
* 1层级的概率为 100%;
* 2层级的概率为 1/4
* 3层级的概率为 1/4 * 1/4
* 后续每增加一层级的概率都是指数级上升
*/
level = zslRandomLevel();
// 扩容层级,随机出来的层级> 当前层级
if (level > zsl->level) {
//这块增加的可能1层,也可能多层,最多(64-当前层级)
for (i = zsl->level; i < level; i++) {
//新添加的层级rank都为0
rank[i] = 0;
//新添加层级取的是zskplist的header对应的指针
update[i] = zsl->header;
//新添加层级的跨度就是元素的总数
update[i]->level[i].span = zsl->length;
}
//更新层级数
zsl->level = level;
}
//给新插入的元素和权重分值创建zskiplistNode,层级为刚随机出来的层级
x = zslCreateNode(level,score,ele);
/**
* 把新插入的节点,插入到每一层级中
* 更新每一层级的链表结构
* 并将新插入节点对应层级的前驱指针和跨度维护进去
*/
for (i = 0; i < level; i++) {
//链表插入节点
x->level[i].forward = update[i]->level[i].forward;
/**
* 新的层级update[i]为 header节点
*/
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
//计算每一层级的跨度并更新进去
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
/**
* 对于没有达到的层级,增加1
*/
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
//新插入节点的回退指针为最底层的前一个节点
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
/**
* 随机层级
* 1层级的概率为 100%;
* 2层级的概率为 1/4
* 3层级的概率为 1/4 * 1/4
* 后续每增加一层级的概率都是指数级上升
* @return
*/
int zslRandomLevel(void) {
int level = 1;
/**
* 完全靠随机, 0xFFFF = 65535 , ZSKIPLIST_P = 0.25
* 如果随机每次随机出来都小于 0.25*65535 level都加1,直到随机出大于
*/
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}总结一下:
- 在操作zset的时候,如果zset为null,则根据redis配置创建一个数据结构为跳跃表或者ziplist结构的zset
- 在创建zset跳跃表结构的时候,会创建一个64层级,权重分值为0,元素为NUll的zskiplistNode作为头节点(这个节点从了当头节点,其他的分值什么的都没有任何意义)
- header节点只是一个位置标识,新插入的节点在level[0]层都会在header后形成一个双向链表
- hader节点不会进入双向链表(一会看图)
- 通过zslInsert将元素插入到跳跃表中
- ①:先找到所有层级中在插入元素分值左侧的元素,并插入到update[]里,然后把跨度填到rank[]中
- ②:随机一个层级出来zslRandomLevel(),最小层级为1
- ③:如果随机的层级>原来的层级,扩容update,新增加的层级为header节点,rank都为0
- ④:创建元素
- ⑤:链表插入,以update[]对应层级的元素为起始点插入元素
- ⑥:如果随机的层级比原来的层级小,上面的层级跨度都得+1
- ⑦:针对最底层也就是level[0] 需要做双向链表的引入
- 这个时候,如果前面的节点是header节点,不做回退指向
- 除了level[0]是一个双向链表
- 其他层级都是一个单向链表
- 通过上面
- 跳跃表不是一个平衡的树
- 极端情况下,跳跃表可能退化为链表,查询复杂度由O(1)降到O(n)
- 业务元素都是在header节点后形成的链表
- 在score相同的情况下,根据元素的长度排序,谁短谁在前
- 插入成功后放入对应zset的 hash表中,key为元素,value为score
- 所以能O(1)的速度拿到元素的对应的权重分值
上图

ADD添加对应的元素
# 语法
ZADD key score member [[score member] [score member] …]
# 添加
zadd yxkong 50 'a' 60 'b' 75 'c' 88 'd' 90 'e' 100 'f'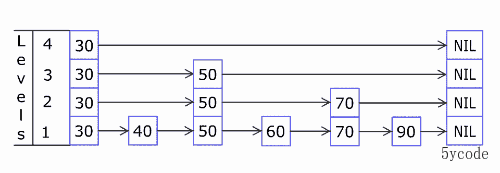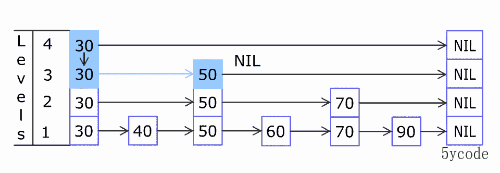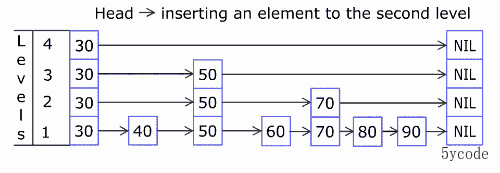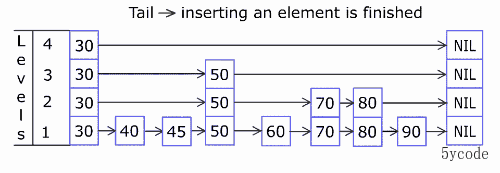
ZRANGEBYSCORE 获取分值在某个区间的元素(以跳跃表为例)
ZRANGEBYSCORE key min max WITHSCORES limit offset num
# min 可以是具体的数值,也可以是-inf(负无穷),也可以是(10
# max 可以是具体的数值,也可以是+inf(正无穷) 也可以是(30
# WITHSCORES 返回元素带score
# limit 限制返回的数量
# offset 从哪个索引开始
# num 返回的数量
如:
office:0>ZRANGEBYSCORE yxkong 55 80 WITHSCORES
1) "b"
2) "60"
3) "c"
4) "75"查看下源码
/**
* 获取指定score区间的元素
* @param c
* @param reverse 是否取反,0表示不取反,1表示取反
*/
void genericZrangebyscoreCommand(client *c, int reverse) {
//将分值区间解析到range中
if (zslParseRange(c->argv[minidx],c->argv[maxidx],&range) != C_OK) {
addReplyError(c,"min or max is not a float");
return;
}
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
......
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//最终都是找链表上的起始点
if (reverse) {
//查找终点 80 50
ln = zslLastInRange(zsl,&range);
} else {
//查找起点 比如 50 80
ln = zslFirstInRange(zsl,&range);
}
//遍历链表,如果有limit就递减,0为假
while (ln && limit--) {
/* Abort when the node is no longer in range. */
//如果获取到的对象权重分值,已经不在范围内了,直接break
if (reverse) {
if (!zslValueGteMin(ln->score,&range)) break;
} else {
if (!zslValueLteMax(ln->score,&range)) break;
}
rangelen++;
//添加到回复缓冲区
addReplyBulkCBuffer(c,ln->ele,sdslen(ln->ele));
if (withscores) {
//需要带权重分值,将权重分值添加到回复缓冲区
addReplyDouble(c,ln->score);
}
/* Move to next node */
//就是正反序遍历链表
if (reverse) {
//回退,永远是level[0]
ln = ln->backward;
} else {
//最底层前进
ln = ln->level[0].forward;
}
}
}
}
/**
* 获取第一个分值所在的节点
* @param zsl
* @param range 50 ~ 80
* @return
*/
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
if (!zslIsInRange(zsl,range)) return NULL;
x = zsl->header;
//从上到下遍历所有的层级,定位到最小的元素
for (i = zsl->level-1; i >= 0; i--) {
/* Go forward while *OUT* of range. */
//定位最小元素所在的位置
while (x->level[i].forward &&
!zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
x = x->level[0].forward;
serverAssert(x != NULL);
/* Check if score <= max. */
if (!zslValueLteMax(x->score,range)) return NULL;
return x;
}查找过程
- ①:找链表的开始位置:通过zsl.level 获取最大的层级,然后倒序遍历层级,然后找到元素的开始或结束位置
- ②:通过开始位置遍历链表
- 如果有数量限制limit>0,递减limit查找,直到limit=0为止
- 在取元素的时候,每次都会判断新遍历的元素的socre是否超范围了
阅读了redis的源码,redis好多地方都是用的近似算法,LFU、LRU、淘汰策略、以及这次的zset,跳跃表的索引也是近似,一但出现了极端情况,跳跃表就直接退化为了链表。
redis系列文章
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了
redis源码阅读五-为什么大量过期key会阻塞redis?
本文是Redis源码剖析系列博文,有想深入学习Redis的同学,欢迎star和关注;
Redis中文注解版:https://github.com/yxkong/redis/tree/5.0
如果觉得本文对你有用,欢迎一键三连;
同时可以关注微信公众号5ycode获取第一时间的更新哦;


文章评论