[TOC]
基础概念
-
为什么要区分内核空间和用户空间?
-
早期是不区分内核和用户的,带来的问题是程序可以访问任意内存空间,如果程序不稳定,容易把系统搞崩溃。
-
后来按cpu指令的重要程度对指令进行了分级,一共4个级别:Ring0~Ring3,linux只使用了Ring0和Ring3两个级别;
-
用户态使用Ring3级别运行,只访问用户空间,Ring0运行在内核态,可以访问任何程序空间
-
-
内核空间
- linux系统内核运行的空间
- 主要提供进程调度、内存分配、连接硬件资源等
-
用户空间
- 提供给应用程序的空间
- 不具备访问内核空间资源的权限
- 需要通过内核空间才能访问到内核资源
- 使用内核资源,cpu需要从用户态切换到内核态,再从内核态到用户态,cpu最少需要切换两次
-
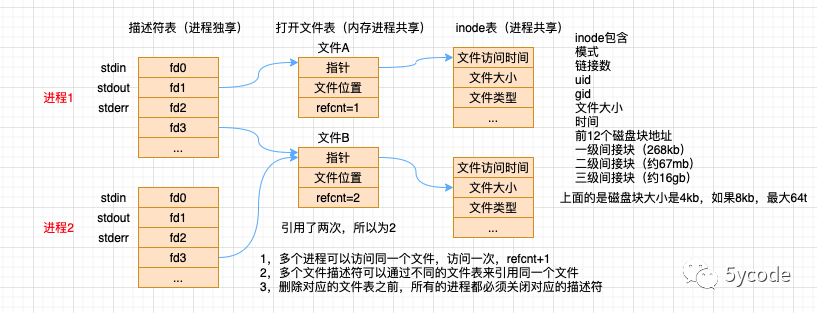
fd(file descriptors文件描述符)
-
指向内核为对应进程维护打开文件记录表的索引值,进程唯一,也可以理解为文件指针
-
file table
- 由系统内核维护的全局唯一的表(一个系统内只有一个)
- 记录所有进程打开文件的状态、偏移量、访问模式、文件位置,该文件对应的inode对象引用
-
inode table
- 全局唯一的表,是硬盘存储的文件的元数据的集合
- 文件类型、文件大小、文件类型、文件锁
-
一切皆文件(进程、设备、通道等)
-
抽象了一组标准接口,每个进程有3个标准文件
- 0 标准输入
- 1 标准输出
- 2 标准错误
- nohup command 2>&1 &
-
fd可以重复利用
-
-
socket的概念
- 特殊的文件(一切皆文件)
- 套接字允许链接到网络,套接字与邮筒和墙壁上的电话插座是类似的
- 必须有一个地址和端口与其绑定
- 双端都建立链接后,两台计算机可以建立一个链接
-
bind()
- redis在启动的时候,通过listenToPort 将配置的ipv4和ipv6以及端口绑定到对应的fd上(可以理解产生一个对外提供服务的fd);
-
listen()
- Redis 通过acceptTcpHandler来监听bind阶段产生的fd到达的tcp请求;
- 一次循环1000次(MAX_ACCEPTS_PER_CALL),每次通过anetTcpAccept中的accept获取达到的tcp请求的fd;
- 将产生的fd绑定到新创建的redisClient上(通过acceptCommonHandler中的createClient创建)
- 这里也会对redis的链接数增加对应的client的个数
-
fork()
- 只是复制主进程的虚拟表空间,仍与父进程共享同样的物理空间;
- 当父子进程某一方放生写操作时,系统才会为其分配物理空间,并复制一份副本以供其修改;
- fork函数的奇妙指出就是仅调用一次,却能够返回两次
- 返回0 表示子进程执行
- 返回1 表示父进程执行
socket示意图:
tcp链接流程
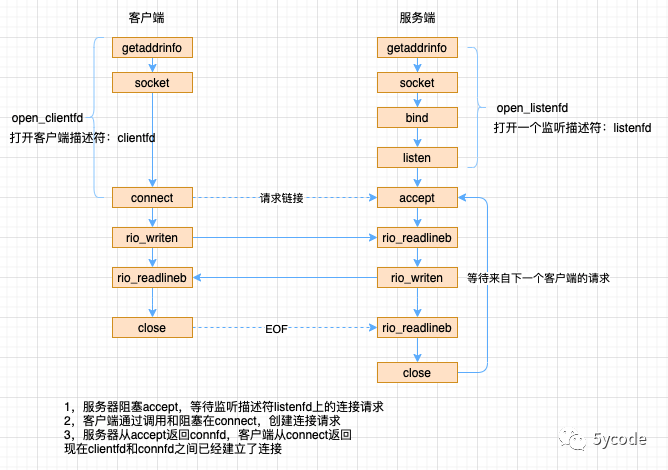
-
io多路复用
- I/O多路复用是一种同步I/O模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知线程进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序。多路是指网络连接,复用指的是同一个线程。
- I/O多路复用模型是建立在内核提供的多路分离函数select/epoll等基础之上的,使用select/epoll函数可以避免同步非阻塞IO模型中轮询等待的问题
- IO多路复用有两个模型
- 一个模型是早期的select和poll,通过集合set去线性循环所有的事件
- 一个是后期的epoll模型,通过注册事件以及事件回调机制处理
redis中的事件驱动模型
/**
* @brief ae的几种实现
* redis按照性能从上到下排序
*
* evport: 支持Solaris
* epoll: 支持linux
* kqueue: 支持FreeBSD 系统 如macos
* select: 都不包含就是select
*/
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endifredis 对于事件模型的封装
/**
* @brief
* 根据不同的操作系统会有不同的实现
* 对于select来说应该是就是初始化fdset,用于select的相关调用;
* 对于epoll来说,需要创建epoll的fd以及epoll使用的events数组
* @param eventLoop
* @return int
*/
static int aeApiCreate(aeEventLoop *eventLoop) {}
/**
* @brief 注册事件到 到操作系统,每个操作系统针对读写的事件类型不同
* 对于evport来说,往npending里增加fd
* 对于kqueue来说,就是往kqfd里增加fd
* 对于select来说,就是往对应读写类型的fd_set里面增加fd
* 对于epoll来说,就是在events中增加/修改感兴趣的事件
* @param eventLoop 是为了接收回调数据
* @param fd 对应监听的fd值
* @param mask 类型
* @return int
*/
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {}
/**
* @brief 单位时间内监听到的事件数量
* @param eventLoop
* @param tvp 单位时间
* @return int 返回待处理的事件数量
*/
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {}
//删除事件
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask) {}
static void aeApiFree(aeEventLoop *eventLoop) {}
//获取实现的名称
static char *aeApiName(void) {}select和poll的缺点:
- 单个进程打开的fd是有限制的,通过fd_setsize设置,默认1024
- 每次调用select,都需要把fd集合从用户态copy到内核态
- 然后在内核遍历(线性扫描,采用轮训的方法)传递进来的fd集合;
epoll改进了select模式,避免了以上的几个缺点(事件驱动)
- epoll所支持的fd上限是最大可打开文件的数目,这个数字,可以在操作系统配置,通过ulimit -a查看(实际上redis通过MAX_ACCEPTS_PER_CALL限制了一次处理的请求数)
- epoll通过epoll_ctl函数,每次注册新的事件到epoll句柄的时候,都会把对应的fd copy到内核中,epoll保证了每个fd在整个过程中只copy一次;
- 默认通过LT模式遍历扫描:epoll_wait监测到fd事件发生后会通知应用程序,应用程序可以不立即处理该事件,下次调用会再次响应
redis的线程模型
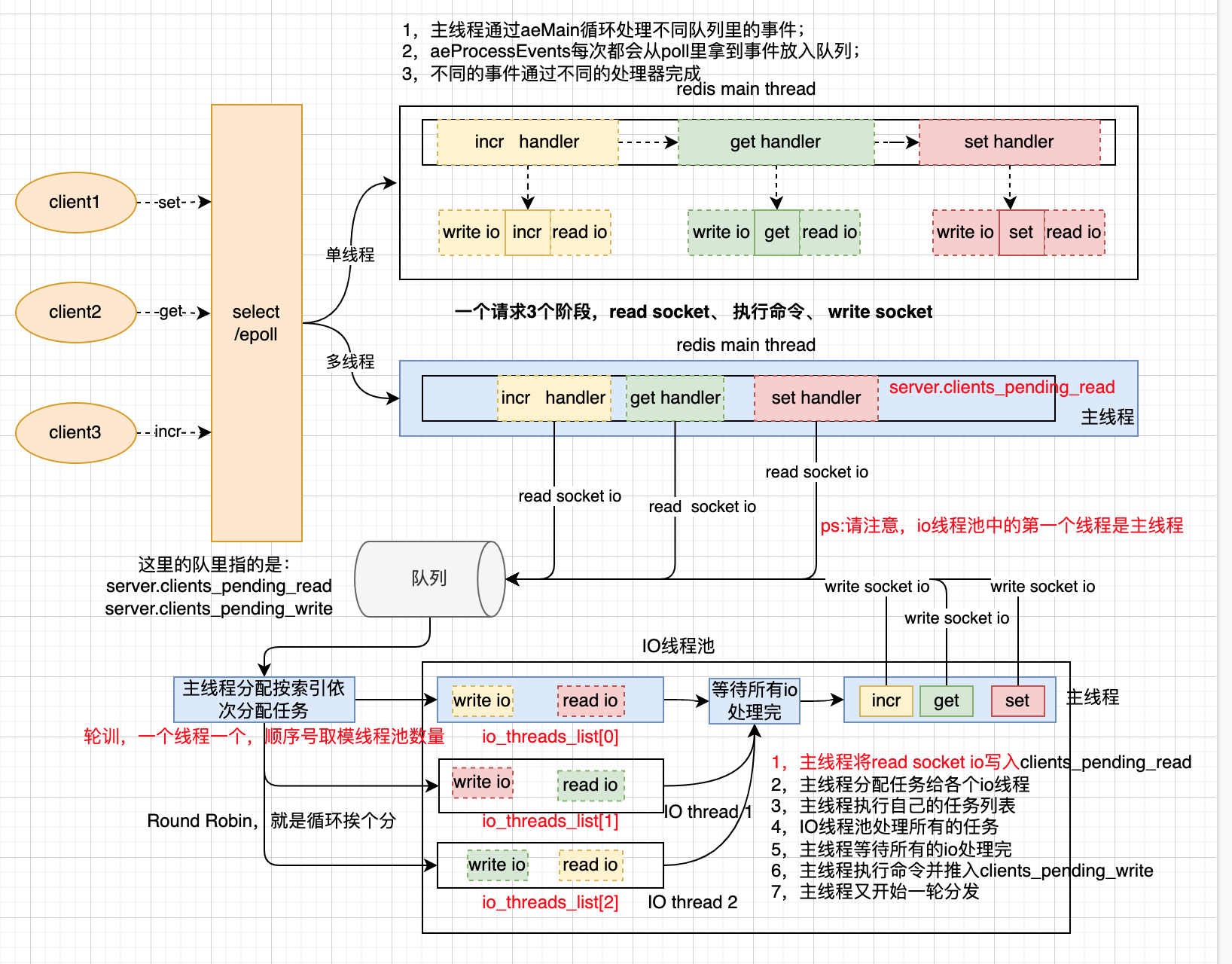
如上图:
- 5.0以及5.0之前的线程模型是单线程的,都是通过主线程在处理读I/O,执行命令,写I/O;
- 6.0以后,redis增加了一个工作线程组(主线程是工作线程的第一个线程)
- 主线程通过aeApiPoll从select/epoll中获取到就绪的事件读写事件(工作线程池,只处理读写I/O)
- 然后主线程将任务扔到队列里
- 主线程通过从队列获取数据依次分给工作线程池里的线程
- 通过计数器等待所有的线程执行完
- 然后主线程挨个执行对应的命令(有序性能保证)
- 主线程执行完命令后,将写I/O再次写入队列
- 然后再次按读I/O的模式处理
redis为什么那么快?
- 纯内存操作
- 使用I/O多路复用+事件模型+非阻塞I/O(利用操作系统的特性,性能高)
- 业务执行单线程模型(避免不必要的上下文切换)
- 高效的数据结构+合理的数据编码
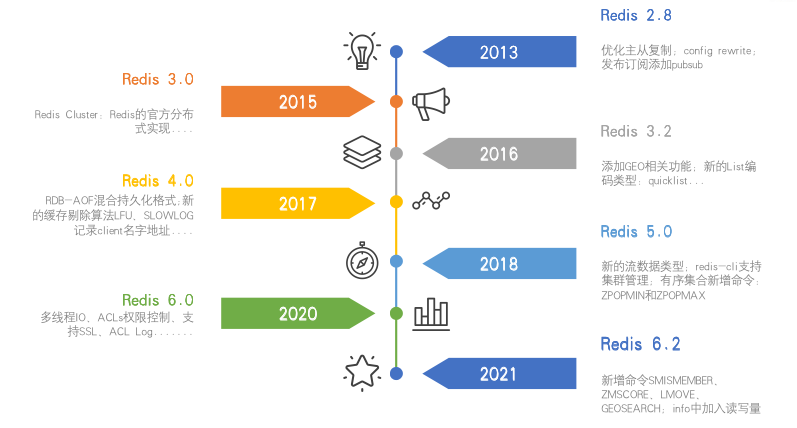
redis 的发展史
redis是如何运行的?
启动流程
精简流程
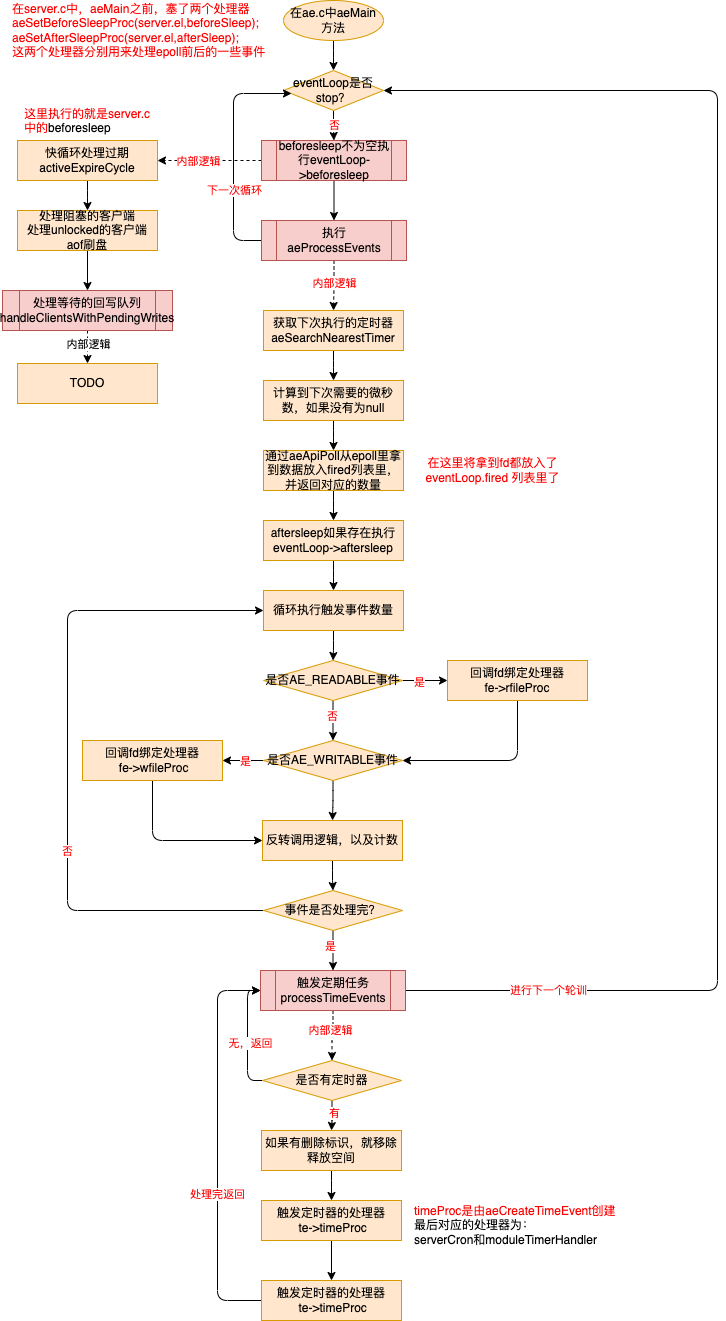
核心代码
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
//只要没有停止,就循环执行,这个是主线程
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
//每次循环前执行beforesleep
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}处理tcp请求
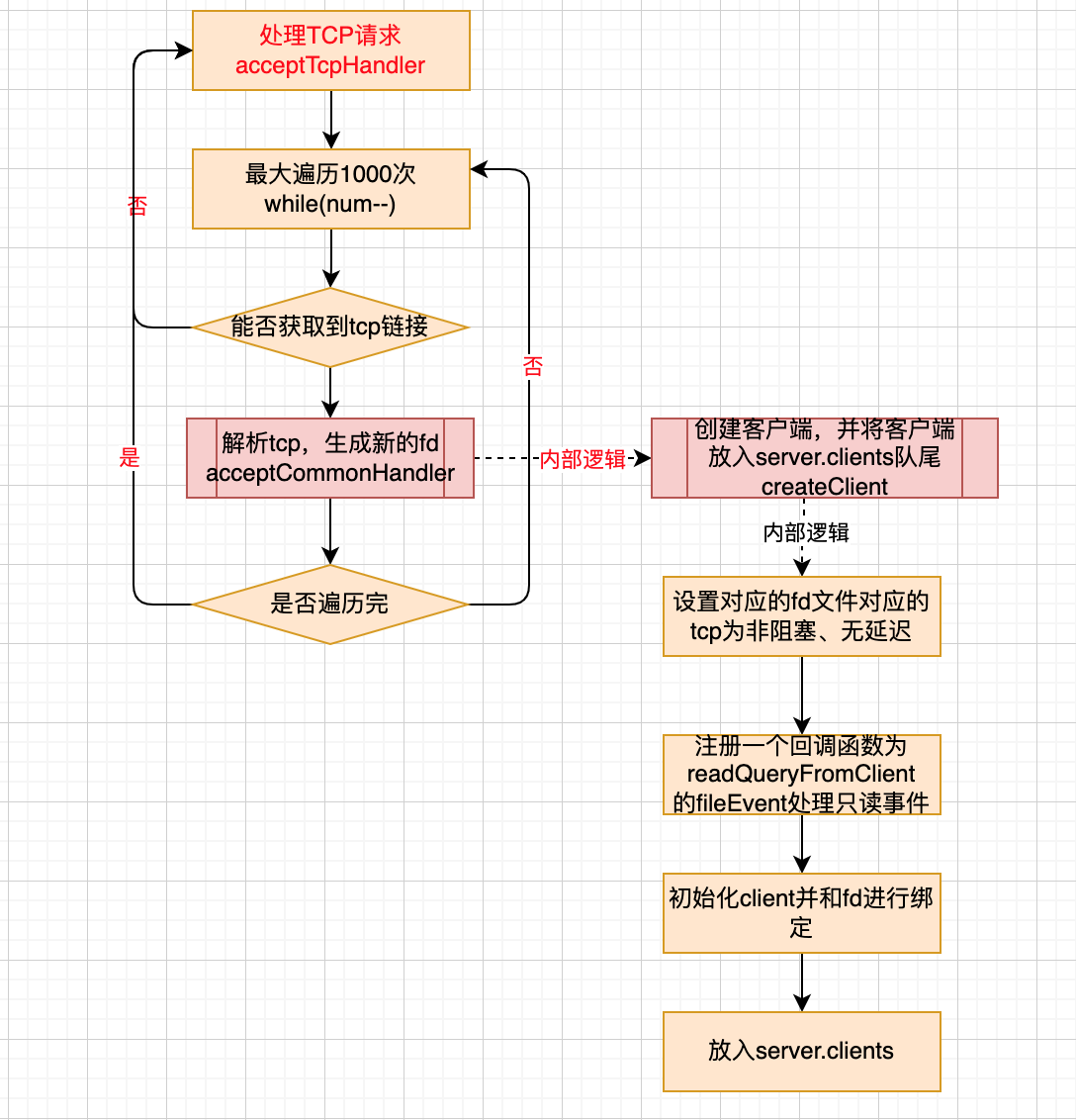
- 在这里将请求转换成了client,并生成了一个fd与其绑定
/**
* @brief tcp处理器
* @param el
* @param fd 当前tcp的fd
* @param privdata 对应epoll数据
* @param mask
*/
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
/**
* cport 当前的端口
* cfd 当前的fd
* max 一次最多处理1000个
*/
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
//取tcp请求
while(max--) {
/**
* @brief 监听tcp socket ,获取一个新的fd,后续再研究下这里 TODO
* 新的fd就是一个有效的链接
*/
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
//针对新监听到的请求处理(创建一个client并将新生成的cfd与其绑定)
acceptCommonHandler(cfd,0,cip);
}
}时间事件的产生
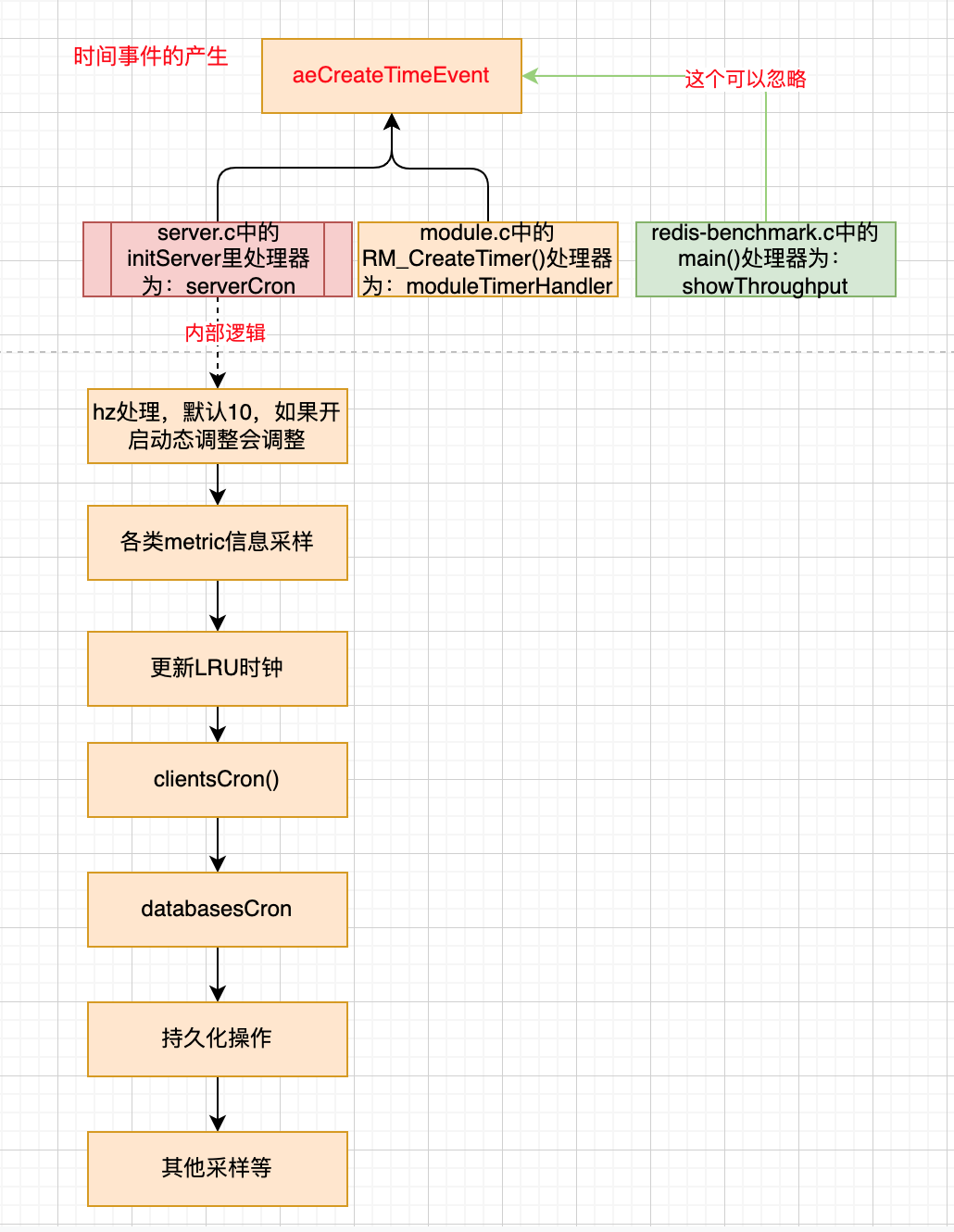
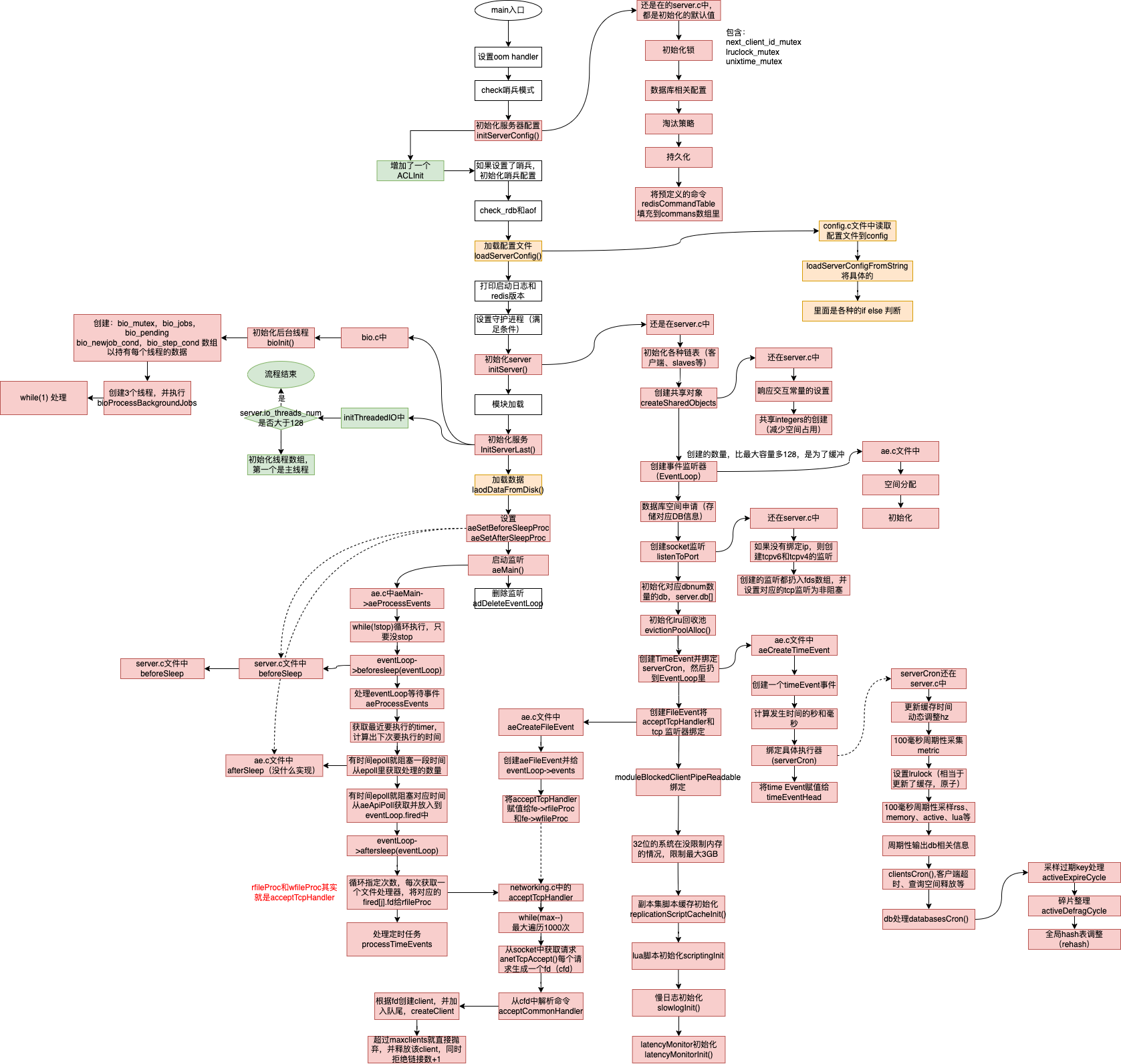
单线程启动流程
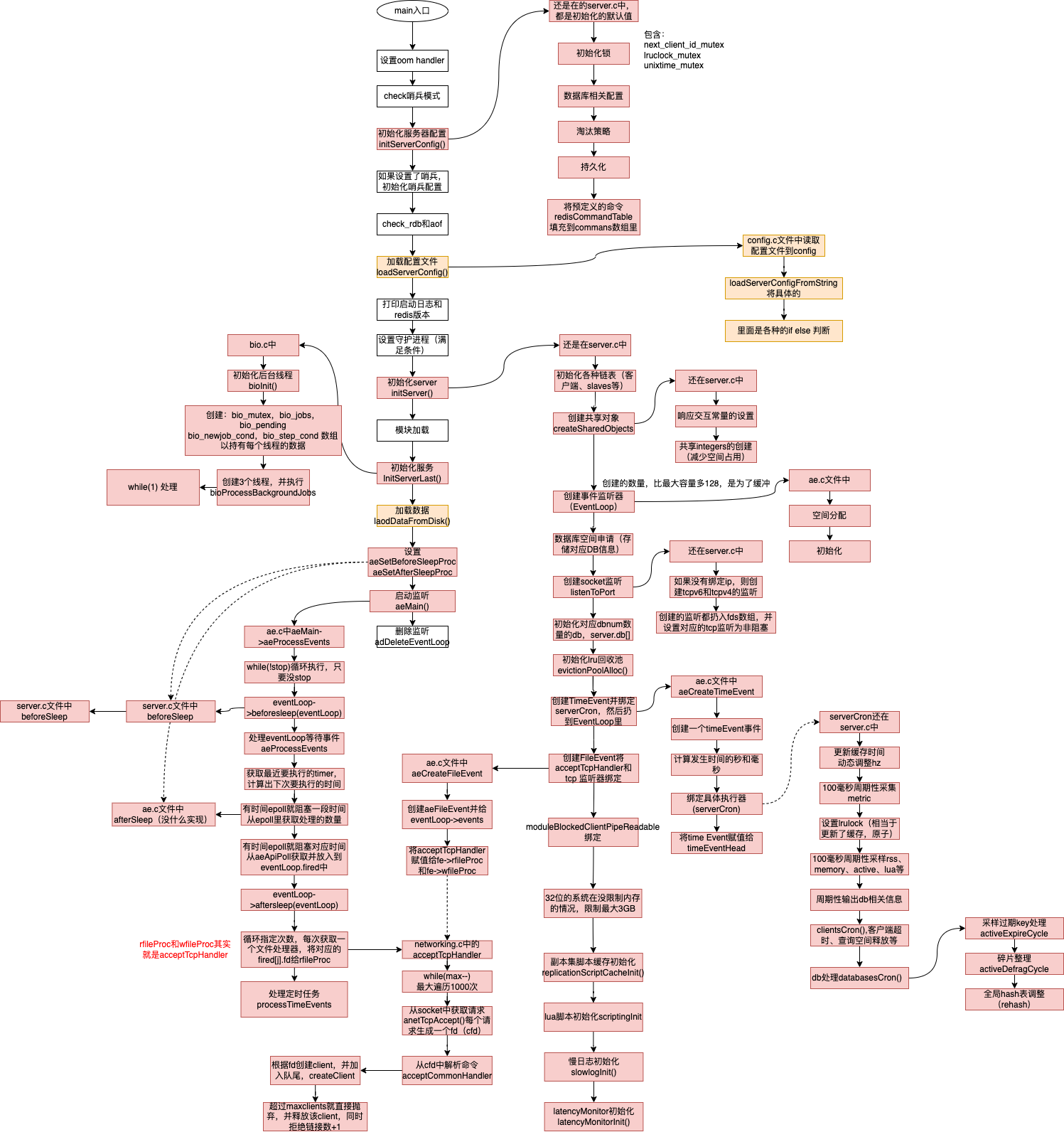
redis多线程启动流程
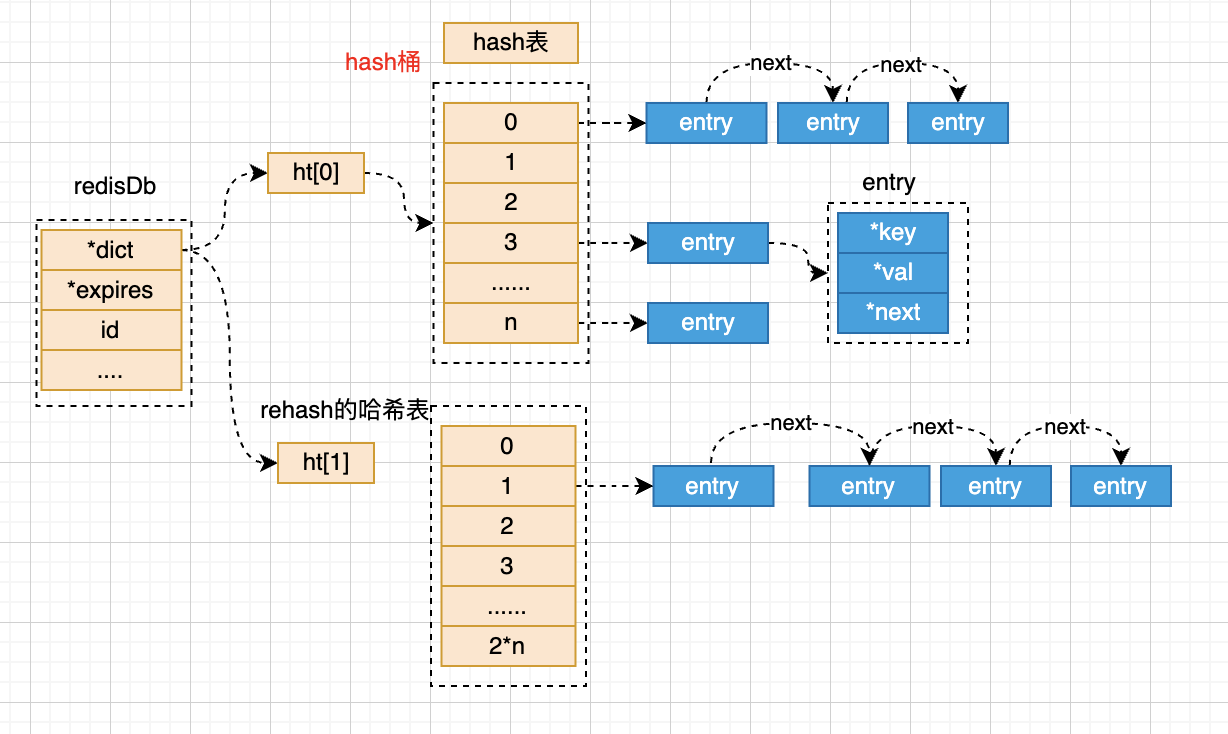
redis存储的基本结构
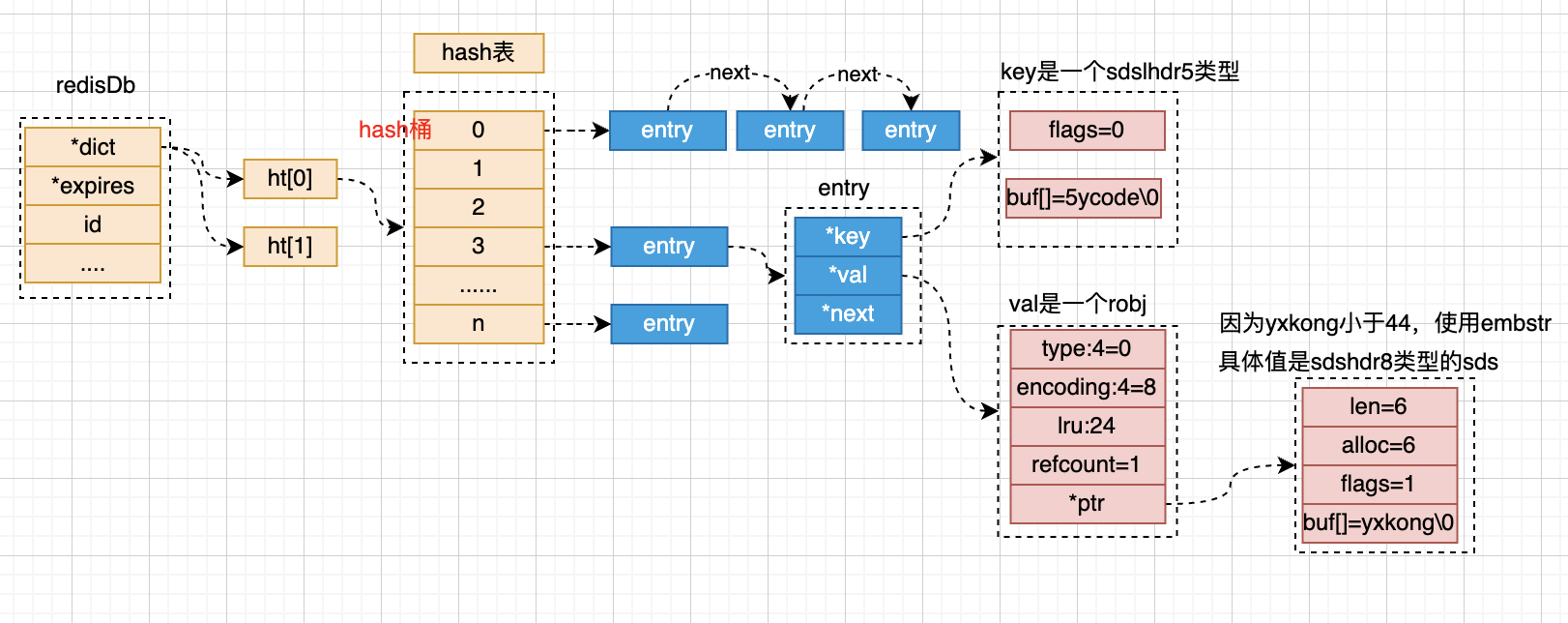
- 一个redisDb代表着一个数据库,默认redis配置16个DB;
- *dict 表示存储所有的key的;
- ht[0] 表示正常使用的hash通;
- redis通过拉链法解决hash冲突;
- entry 代表的是一个链表中的一个节点,包含key 和val的指针;
- key是一个sds类型的字符串(不预留空间,节省空间)
- val是一个包装的redisObj对象
- ht[1] 是redis在进行rehash的时候,临时存放的节点,rehash后会改到ht[0]
- ht[0] 表示正常使用的hash通;
- *expires 会存储一份带有过期时间的key;
- 结构和*dict中的一样
typedef struct dictEntry {
void *key;
// v使用联合体,共用头部指针,正常是4选一,可以理解为java的泛型
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
/**
* @brief redis对象的数据结构体,在监听到数据后,都会将key和value包装成这个对象
* OBJ_STRING -> OBJ_ENCODING_INT 使用整数值实现的字符串对象
* OBJ_STRING -> OBJ_ENCODING_RAW 使用sds实现的字符串对象
* OBJ_STRING -> OBJ_ENCODING_EMBSTR 使用embstr编码的sds实现的字符串
* OBJ_LIST -> OBJ_ENCODING_QUICKLIST 使用快速列表实现(混合了压缩列表和双端链表)
* OBJ_SET -> OBJ_ENCODING_HT 使用字典实现的集合
* OBJ_SET -> OBJ_ENCODING_INTSET 使用整数集合实现的集合
* OBJ_ZSET -> OBJ_ENCODING_ZIPLIST 使用压缩列表实现的有序集合
* OBJ_ZSET -> OBJ_ENCODING_SKIPLIST 使用跳表实现的有序集合
* OBJ_HASH -> OBJ_ENCODING_HT 使用字典实现的hash
* OBJ_HASH -> OBJ_ENCODING_ZIPLIST 使用压缩列表实现的hash
* OBJ_MODULE
* OBJ_STREAM -> OBJ_ENCODING_STREAM 使用stream实现
*/
typedef struct redisObject {
//robj存储的对象类型,sting、list、set、zset等
unsigned type:4; //4位
// 编码,OBJ_ENCODING_RAW 0 OBJ_ENCODING_INT 1
unsigned encoding:4; //4位
/**
* @brief 24位
* LRU的策略下:lru存储的是 秒级时间戳的低24位,约194天会溢出
* LFU的策略下:24位拆为两块,高16位(最大值65535)低8位(最大值255)
* 高16存储的是 存储的是分钟级&最大存储位的值,要溢出的话,需要65535%60%24 约 45天溢出
* 低8位存储的是近似统计位
* 在lookupKey进行更新
*/
unsigned lru:LRU_BITS;
//引用次数,当为0的时候可以释放就,c语言没有垃圾回收的机制,通过这个可以释放空间
int refcount; //4字节
/**
* 指针有两个属性
* 1,指向变量/对象的地址;
* 2,标识变量/地址的长度;
* void 因为没有类型,所以不能判断出指向对象的长度
*/
void *ptr; // 8字节
} robj;//一个robj 占16字节
typedef struct client {
uint64_t id; /* Client incremental unique ID. */
int fd; /* Client socket. */
redisDb *db; /* Pointer to currently SELECTed DB. */
robj *name; /* As set by CLIENT SETNAME. */
//初始的时候,是一个空的sds,客户端累计的查询缓冲区大小,后续每次处理扩容16kb
sds querybuf; /* Buffer we use to accumulate client queries. */
//从querybuf读取的位置
size_t qb_pos; /* The position we have read in querybuf. */
//待同步到从库的缓冲区到小
sds pending_querybuf; /* If this client is flagged as master, this buffer
represents the yet not applied portion of the
replication stream that we are receiving from
the master. */
//上次查询缓冲区使用的大小
size_t querybuf_peak; /* Recent (100ms or more) peak of querybuf size. */
//参数数量
int argc; /* Num of arguments of current command. */
//参数的redisObject 数组
robj **argv; /* Arguments of current command. */
//客户端要执行的命令
struct redisCommand *cmd, *lastcmd; /* Last command executed. */
int reqtype; /* Request protocol type: PROTO_REQ_* */
int multibulklen; /* Number of multi bulk arguments left to read. */
long bulklen; /* Length of bulk argument in multi bulk request. */
/**
* @brief 链表对象是里面的节点对象是clientReplyBlock
* clientReplyBlock是一个数组
* 因为不知道缓冲区有多大,为了
*/
list *reply; /* List of reply objects to send to the client. */
unsigned long long reply_bytes; /* Tot bytes of objects in reply list. */
size_t sentlen; /* Amount of bytes already sent in the current
buffer or object being sent. */
time_t ctime; /* Client creation time. */
/**
* @brief 上次交互的时间,用于判断超时
*/
time_t lastinteraction; /* Time of the last interaction, used for timeout */
time_t obuf_soft_limit_reached_time;
.....
/* Response buffer */
int bufpos;
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;redis支持的数据类型
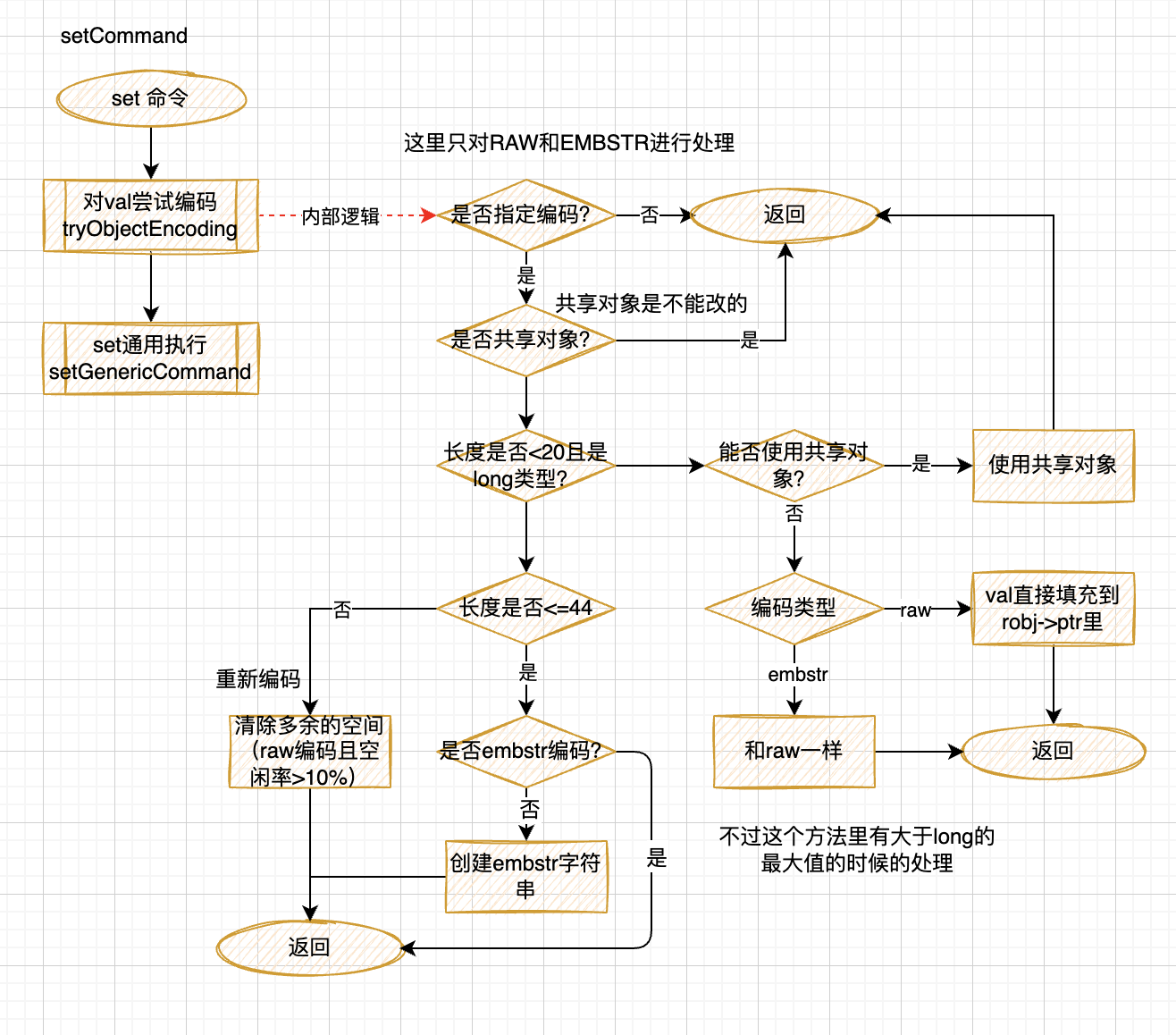
Redis是一个开源,内存存储的数据结构服务,可用作数据库(不建议),高速缓存和消息队列等。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglog、stream等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
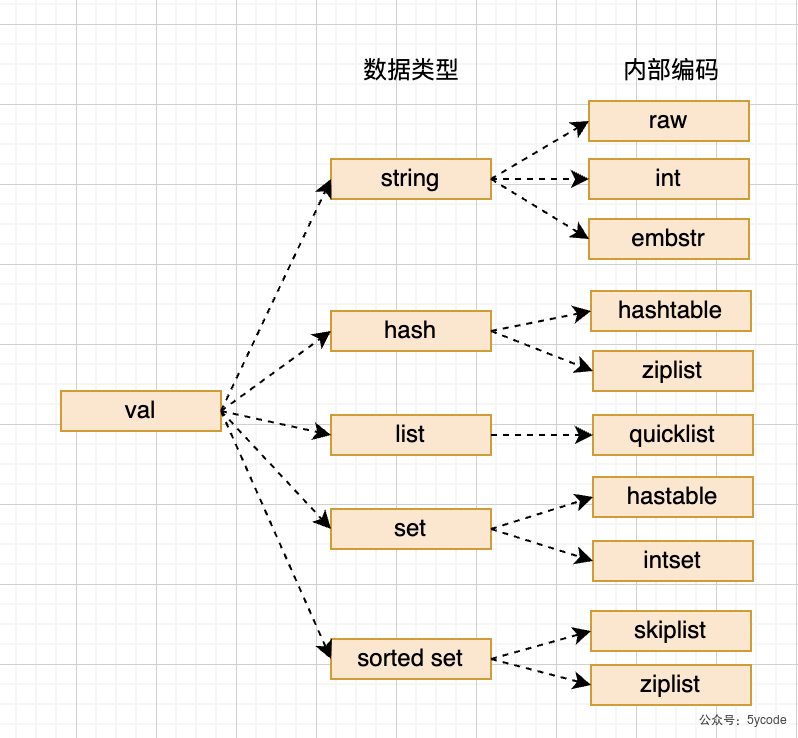
string (sds)
通过sds动态字符串编码实现。
- string类型分为embstr和raw两种编码,
- 小于44字节,用embstr编码(一次空间申请,空间紧凑)
- 大于44字节,使用raw编码
- 数值类型使用int编码
struct __attribute__ ((__packed__)) sdshdr8 {
//1字节 max= 255 已用空间(不同类型len占用的长度不同)
uint8_t len; /* used */
//1字节 申请的buf的总空间,max255(不包含flags、len、alloc这些)(不同类型len占用的长度不同)
uint8_t alloc; /* excluding the header and null terminator */
// 1字节 max= 255
unsigned char flags; /* 3 lsb of type, 5 unused bits */
// 字节数组+1结尾\0
char buf[];
};//4+n 长度
struct __attribute__ ((__packed__)) sdshdr16 {
// 2字节 16位 max 65535(不同类型len占用的长度不同)
uint16_t len; /* used */
// 2字节 16位 申请的buf的总空间max 65535
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
sds高效在哪了?
必须了解下c语言的字符串。
- 在c语言中没有字符串的概念,只有一个字符数组
- c语言中字符串的结束以'\0' 标记,字符有多长?每次都得循环遍历到\0 才能获取
- c语言的字符串不能存储二进制数据;
sds做了哪些优化?
- 将长度获取降为O(1),通过len可以直接获取存储的数据长度;
- 空间预分配
- 这也是redis里叫简单动态字符串的根因
- 由不同的sdshdr类型组成,其中len和alloc根据类型不同,占用的位数不同,buf数组就为申请空间的长度
- redis在创建字符串的时候,使用最小原则去匹配对应的sdshdr(ps:key的sds生成比较特殊,直接申请固定长度的空间len和alloc相同),未填满的空间就是预留的buffer;
- 当内容值改变的时候,如果改变后的值未超出总长度,就直接在对应的内存上操作,不会再申请新的空间,如果超过,就得变换类型
应用场景
- 缓存
- 计数器
- 共享session
- 分布式锁
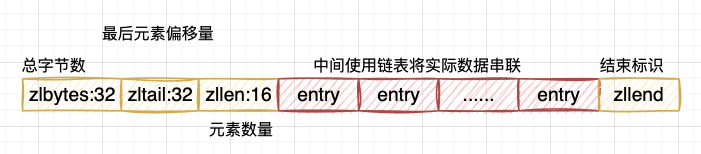
list
redis3.2以后将list的压缩列表(ziplist)和双端链表(linkedList)改成了quicklist了。
-
quicklist融合了ziplist和linkedlist的功能;
-
默认一个quicklistNode是一个ziplist对象;
-
ziplist的大小有限制
- 不能保存过多的元素(否则O(n)的查询复杂度会很慢)
- 不能保存过大的元素(过大,装不了几个元素)
-
ziplist更新会比较麻烦(比如更新值不等于当前元素内存大小时,需要扩缩容,或挪移,如果多个连续更新,想下效率)
- 扩缩容,会引起数据的挪移,内存数据的搬迁
先看下原来ziplist的的创建,以及结构
/**
* @brief 创建一个空的压缩列表
*
* @return unsigned char*
*/
unsigned char *ziplistNew(void) {
// <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
//压缩列表的结构大小 12+1
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
//申请13字节的空间,ziplist的 head + 结束标识的大小
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
//将列表尾设置为255
zl[bytes-1] = ZIP_END;
return zl;
}
再看下quicklist的源码和结构
typedef struct quicklist {
//头节点指针
quicklistNode *head;
//尾节点指针
quicklistNode *tail;
//元素个数总和
unsigned long count; /* total count of all entries in all ziplists */
//快速列表的节点个数
unsigned long len; /* number of quicklistNodes */
//压缩列表的最大大小,初始化时用的,list-max-ziplist-size的值
int fill : 16; /* fill factor for individual nodes */
//结点压缩深度,初始化时用的 list-compress-depth 的值,0表示不压缩
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
/**
* 快速列表的节点结构
*/
typedef struct quicklistNode {
//前驱节点指针
struct quicklistNode *prev;
//后继节点指针
struct quicklistNode *next;
//指向压缩列表的指针(当前节点被压缩,指向一个quicklistLZF结构的指针)
unsigned char *zl;
//压缩列表所占字节总数
unsigned int sz; /* ziplist size in bytes */
//压缩列表中的元素数量
unsigned int count : 16; /* count of items in ziplist */
//编码,原生字节数组为1,压缩存储为2
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//表示quicklistNode 节点是否采用ziplist结构保存数据,
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//是否再次压缩,不设置,表示ziplist结构,设置为1表示quicklistLZF,
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistLZF {
//表示被压缩后的ziplist的大小
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;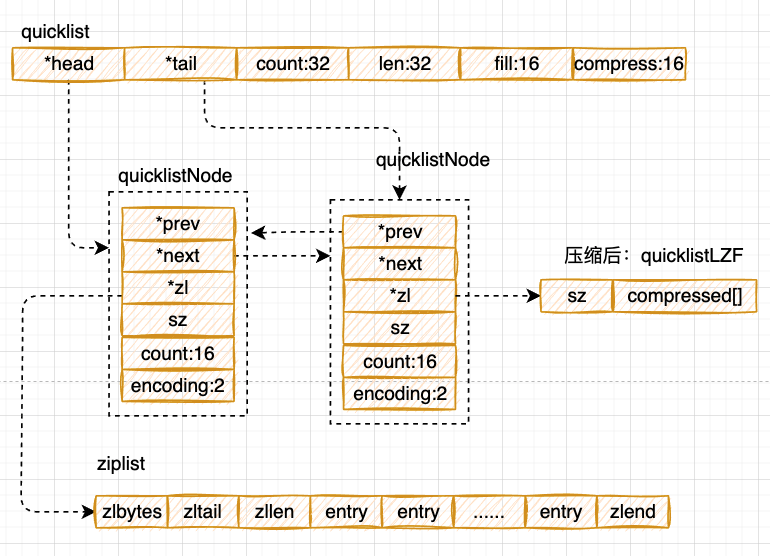
如上:
- quicklist解决了压缩列表插入扩缩容的问题(链表指针,不用考虑空间,不用考虑挪移)
- quicklist解决了压缩列表容量的问题,
应用场景
- 消息队列
- 文章列表
set
/**
* 创建set的工厂方法
* @param value
* @return
*/
robj *setTypeCreate(sds value) {
//是一个long类型的,创建成intset
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
return createIntsetObject();
return createSetObject();
}
/**
* 创建一个普通hash表
* @return
*/
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;
return o;
}
/**
* 创建一个intset
* @return
*/
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
/**
* intset的数据结构
*/
typedef struct intset {
//编码方式,可以是16位整数,32位整数,64位整数
uint32_t encoding;
//元素个数
uint32_t length;
//存储的是数组指针,按从小到大排列
int8_t contents[];
} intset;这里只介绍下intset
- 在intset中,保存的是当前intset最大的编码类型
- length是数组的长度
- contents 是数组的指针
- 按从小达到排列,不重复,具备唯一性
- 插入时通过二分查找定位
应用场景
-
唯一性
-
共同(好友、独立ip、标签)
zset
主要讲解下跳跃表结构,压缩表不讲解
/**
* 跳跃表节点
*/
typedef struct zskiplistNode {
//member对象
sds ele;
//权重分值
double score;
//后退指针
struct zskiplistNode *backward;
//层级描述
struct zskiplistLevel {
//前进指针
struct zskiplistNode *forward;
//跨越节点的数量
unsigned long span;
} level[];
} zskiplistNode;
/**
* zset的数据结构跳跃表
*/
typedef struct zskiplist {
//头尾节点指针
struct zskiplistNode *header, *tail;
//节点数量
unsigned long length;
//最大层数
int level;
} zskiplist;
/**
* 跳表结构的zset
*/
typedef struct zset {
//kv形式,存储所有的member和对应的score
dict *dict;
//跳跃表
zskiplist *zsl;
} zset;zadd添加数据流程
我们从源码zadd看下zset命令(精简后的源码),在t_zset.c中
void zaddGenericCommand(client *c, int flags) {
//不存在,就创建
if (zobj == NULL) {
/**
* 根据redis的配置,如果有序集合不使用ziplist存储或者第一次插入元素的个数大于设置的ziplist最大长度,则使用跳表
*/
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)){
//这里创建了一个score为0,层级为64的元素为null的 头节点
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
//插入entry到hash表
dbAdd(c->db,key,zobj);
} else {//存在,校验类型,不是zset,报错
if (zobj->type != OBJ_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
//遍历所有的<element,score>
for (j = 0; j < elements; j++) {
double newscore;
score = scores[j];
int retflags = flags;
//获取元素数据的指针
ele = c->argv[scoreidx+1+j*2]->ptr;
//添加元素到zset,在zsetAdd 方法里进行了类型区分
int retval = zsetAdd(zobj, score, ele, &retflags, &newscore);
if (retval == 0) {
addReplyError(c,nanerr);
goto cleanup;
}
//根据操作类型计数
if (retflags & ZADD_ADDED) added++;
if (retflags & ZADD_UPDATED) updated++;
if (!(retflags & ZADD_NOP)) processed++;
score = newscore;
}
//计数
server.dirty += (added+updated);
}
/**
* zset添加元素
* @param zobj zset的存储结构
* @param score 添加的分值
* @param ele 元素对象
* @param flags
* @param newscore 添加成功后的分值
* @return
*/
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//存在先删后插
}else if (!xx) {
//超过配置长度,就将压缩链表转到了跳跃表
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value ||
!ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*flags |= ZADD_ADDED;
return 1;
}
}
}
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//zset 指针
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
//从zset的全局hash表中查找对应的key,找到说明已经存在,如果需要更新就操作,不需要就返回
de = dictFind(zs->dict,ele);
if (de != NULL) {
if (score != curscore) {
//这里先删除,然后重新插入,单线程保证了一致性,最后插入还是走的zslInsert
znode = zslUpdateScore(zs->zsl,curscore,ele,score);
//更新全局hash表里的权重分值
dictGetVal(de) = &znode->score; /* Update score ptr. */
*flags |= ZADD_UPDATED;
}
}else if (!xx) {
//将元素压缩成一个紧凑型的sds
ele = sdsdup(ele);
//插入元素
znode = zslInsert(zs->zsl,score,ele);
//将元素插入到对应的hash表中
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
*flags |= ZADD_ADDED;
if (newscore) *newscore = score;
return 1;
}
}
}通过源码:
在插入的元素的时候逻辑如下:
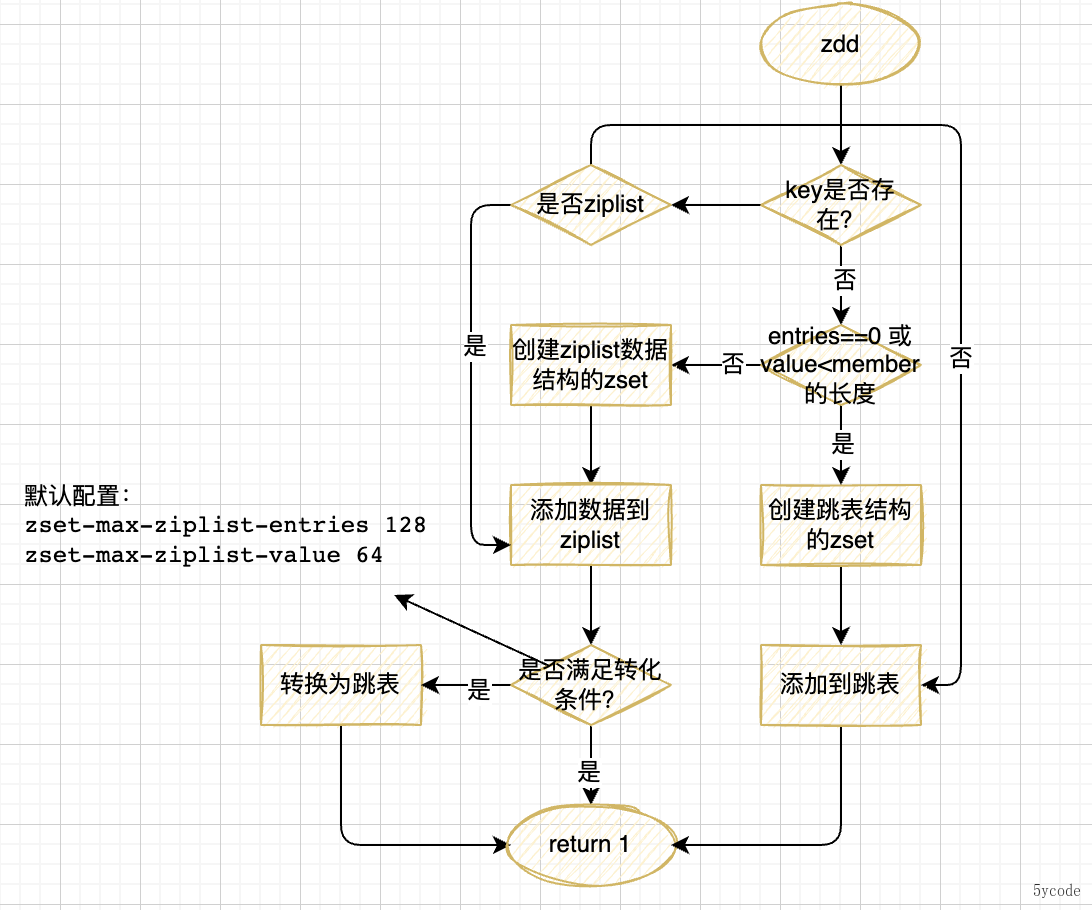
- 如果第一次为空,根据元素的个数创建zset的数据结构,默认是创建ziplist
- 当使用压缩链表ziplist的时候
跳跃表的创建与插入
我们重点看下跳跃表的操作。
跳跃表论文 https://www.cl.cam.ac.uk/teaching/2005/Algorithms/skiplists.pdf
/**
* 创建一个跳跃表(具体实现)
*/
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
// header是一个权重分值为0,元素为NULL的对象
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
//新创建的跳跃表的header是一个64层级的空表
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
/**
* 跳表结构插入一条数据
* @param zsl 从zset上获取到跳跃表
* @param score 权重分值
* @param ele 元素
* @return
*/
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
/**
* update 保存对应层级小于插入权重分值的前一个节点,如果没有为header
* 新添加层级保存的是跳跃表的header指针
* x 表示zskiplistNode节点指针
*/
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
/**
* 每一层对应到update对应层级那个位置的跨度
*/
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
//最开始为头节点
x = zsl->header;
//逆序遍历当前的所有层级,找到新插入权重分值每一层左侧的数据
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
//最上层 rank为0,否则为i+1(相当于逆序了)
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
/**
* 前驱指针存在,
* 并且(当前指针对应的分值小于插入分值 或者(当前分值等于插入分值 并且现有元素和插入元素不相同))
* 比如当前权重分值为 20,跨度5,插入权重分值为30 ,或者 权重分值都为20,但是元素长度不相同(分值相同的话看元素长度大小,小的在前)
* 继续往下一个节点走,会记录下满足条件的跨度
* 通过这块,可以看到在zset里是根据分数权重,然后根据元素的长度大小升序排序
*/
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//将符合条件的层级跨度收集起来
rank[i] += x->level[i].span;
//链表往下走
x = x->level[i].forward;
}
//将每一层的要插入值的最近一个节点更新到update数组里
update[i] = x;
}
/**
* 随机层级
* 1层级的概率为 100%;
* 2层级的概率为 1/4
* 3层级的概率为 1/4 * 1/4
* 后续每增加一层级的概率都是指数级上升
*/
level = zslRandomLevel();
// 扩容层级,随机出来的层级> 当前层级
if (level > zsl->level) {
//这块增加的可能1层,也可能多层,最多(64-当前层级)
for (i = zsl->level; i < level; i++) {
//新添加的层级rank都为0
rank[i] = 0;
//新添加层级取的是zskplist的header对应的指针
update[i] = zsl->header;
//新添加层级的跨度就是元素的总数
update[i]->level[i].span = zsl->length;
}
//更新层级数
zsl->level = level;
}
//给新插入的元素和权重分值创建zskiplistNode,层级为刚随机出来的层级
x = zslCreateNode(level,score,ele);
/**
* 把新插入的节点,插入到每一层级中
* 更新每一层级的链表结构
* 并将新插入节点对应层级的前驱指针和跨度维护进去
*/
for (i = 0; i < level; i++) {
//链表插入节点
x->level[i].forward = update[i]->level[i].forward;
/**
* 新的层级update[i]为 header节点
*/
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
//计算每一层级的跨度并更新进去
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
/**
* 对于没有达到的层级,增加1
*/
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
//新插入节点的回退指针为最底层的前一个节点
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
/**
* 随机层级
* 1层级的概率为 100%;
* 2层级的概率为 1/4
* 3层级的概率为 1/4 * 1/4
* 后续每增加一层级的概率都是指数级上升
* @return
*/
int zslRandomLevel(void) {
int level = 1;
/**
* 完全靠随机, 0xFFFF = 65535 , ZSKIPLIST_P = 0.25
* 如果随机每次随机出来都小于 0.25*65535 level都加1,直到随机出大于
*/
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}总结一下:
- 在操作zset的时候,如果zset为null,则根据redis配置创建一个数据结构为跳跃表或者ziplist结构的zset
- 在创建zset跳跃表结构的时候,会创建一个64层级,权重分值为0,元素为NUll的zskiplistNode作为头节点(这个节点从了当头节点,其他的分值什么的都没有任何意义)
- header节点只是一个位置标识,新插入的节点在level[0]层都会在header后形成一个双向链表
- hader节点不会进入双向链表(一会看图)
- 通过zslInsert将元素插入到跳跃表中
- ①:先找到所有层级中在插入元素分值左侧的元素,并插入到update[]里,然后把跨度填到rank[]中
- ②:随机一个层级出来zslRandomLevel(),最小层级为1
- ③:如果随机的层级>原来的层级,扩容update,新增加的层级为header节点,rank都为0
- ④:创建元素
- ⑤:链表插入,以update[]对应层级的元素为起始点插入元素
- ⑥:如果随机的层级比原来的层级小,上面的层级跨度都得+1
- ⑦:针对最底层也就是level[0] 需要做双向链表的引入
- 这个时候,如果前面的节点是header节点,不做回退指向
- 除了level[0]是一个双向链表
- 其他层级都是一个单向链表
- 通过上面
- 跳跃表不是一个平衡的树
- 极端情况下,跳跃表可能退化为链表,查询复杂度由O(1)降到O(n)
- 业务元素都是在header节点后形成的链表
- 在score相同的情况下,根据元素的长度排序,谁短谁在前
- 插入成功后放入对应zset的 hash表中,key为元素,value为score
- 所以能O(1)的速度拿到元素的对应的权重分值
上图
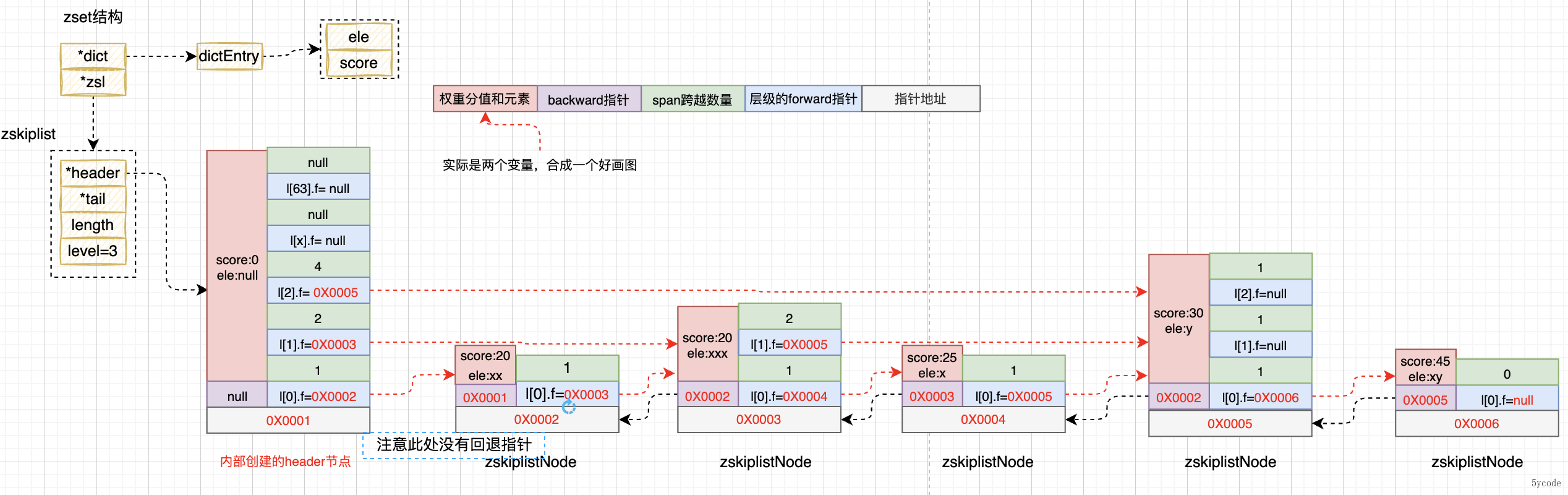
ADD添加对应的元素
# 语法
ZADD key score member [[score member] [score member] …]
# 添加
zadd yxkong 50 'a' 60 'b' 75 'c' 88 'd' 90 'e' 100 'f'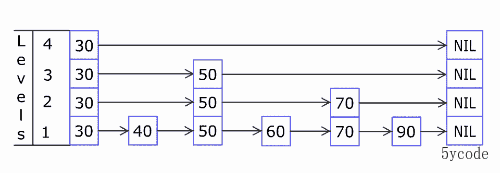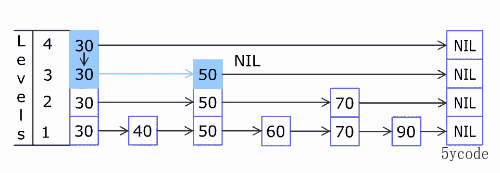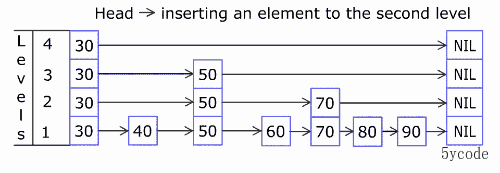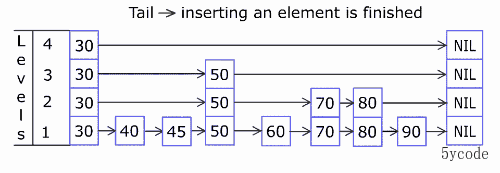
ZRANGEBYSCORE 获取分值在某个区间的元素(以跳跃表为例)
ZRANGEBYSCORE key min max WITHSCORES limit offset num
# min 可以是具体的数值,也可以是-inf(负无穷),也可以是(10
# max 可以是具体的数值,也可以是+inf(正无穷) 也可以是(30
# WITHSCORES 返回元素带score
# limit 限制返回的数量
# offset 从哪个索引开始
# num 返回的数量
如:
office:0>ZRANGEBYSCORE yxkong 55 80 WITHSCORES
1) "b"
2) "60"
3) "c"
4) "75"查看下源码
/**
* 获取指定score区间的元素
* @param c
* @param reverse 是否取反,0表示不取反,1表示取反
*/
void genericZrangebyscoreCommand(client *c, int reverse) {
//将分值区间解析到range中
if (zslParseRange(c->argv[minidx],c->argv[maxidx],&range) != C_OK) {
addReplyError(c,"min or max is not a float");
return;
}
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
......
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//最终都是找链表上的起始点
if (reverse) {
//查找终点 80 50
ln = zslLastInRange(zsl,&range);
} else {
//查找起点 比如 50 80
ln = zslFirstInRange(zsl,&range);
}
//遍历链表,如果有limit就递减,0为假
while (ln && limit--) {
/* Abort when the node is no longer in range. */
//如果获取到的对象权重分值,已经不在范围内了,直接break
if (reverse) {
if (!zslValueGteMin(ln->score,&range)) break;
} else {
if (!zslValueLteMax(ln->score,&range)) break;
}
rangelen++;
//添加到回复缓冲区
addReplyBulkCBuffer(c,ln->ele,sdslen(ln->ele));
if (withscores) {
//需要带权重分值,将权重分值添加到回复缓冲区
addReplyDouble(c,ln->score);
}
/* Move to next node */
//就是正反序遍历链表
if (reverse) {
//回退,永远是level[0]
ln = ln->backward;
} else {
//最底层前进
ln = ln->level[0].forward;
}
}
}
}
/**
* 获取第一个分值所在的节点
* @param zsl
* @param range 50 ~ 80
* @return
*/
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
if (!zslIsInRange(zsl,range)) return NULL;
x = zsl->header;
//从上到下遍历所有的层级,定位到最小的元素
for (i = zsl->level-1; i >= 0; i--) {
/* Go forward while *OUT* of range. */
//定位最小元素所在的位置
while (x->level[i].forward &&
!zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
x = x->level[0].forward;
serverAssert(x != NULL);
/* Check if score <= max. */
if (!zslValueLteMax(x->score,range)) return NULL;
return x;
}查找过程
- ①:找链表的开始位置:通过zsl.level 获取最大的层级,然后倒序遍历层级,然后找到元素的开始或结束位置
- ②:通过开始位置遍历链表
- 如果有数量限制limit>0,递减limit查找,直到limit=0为止
- 在取元素的时候,每次都会判断新遍历的元素的socre是否超范围了
阅读了redis的源码,redis好多地方都是用的近似算法,LFU、LRU、淘汰策略、以及这次的zset,跳跃表的索引也是近似,一但出现了极端情况,跳跃表就直接退化为了链表。
应用场景
- 排行榜
- 限流
- 带权重的队列
- 延迟队列
hash
我们先看下源码
void hsetCommand(client *c) {
//遍历所有的kv
for (i = 2; i < c->argc; i += 2)
// 创建hash的key val
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
}
int hashTypeSet(robj *o, sds field, sds value, int flags) {
//ziplist处理逻辑
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
}else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
//如果存在,先释放,再把新的sds的指针赋值过去
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
} else {
dictAdd(o->ptr,f,v);
}
}
}对应的图,可以参考下存储的基本结构那
应用场景
- 缓存
redis的订阅与发布
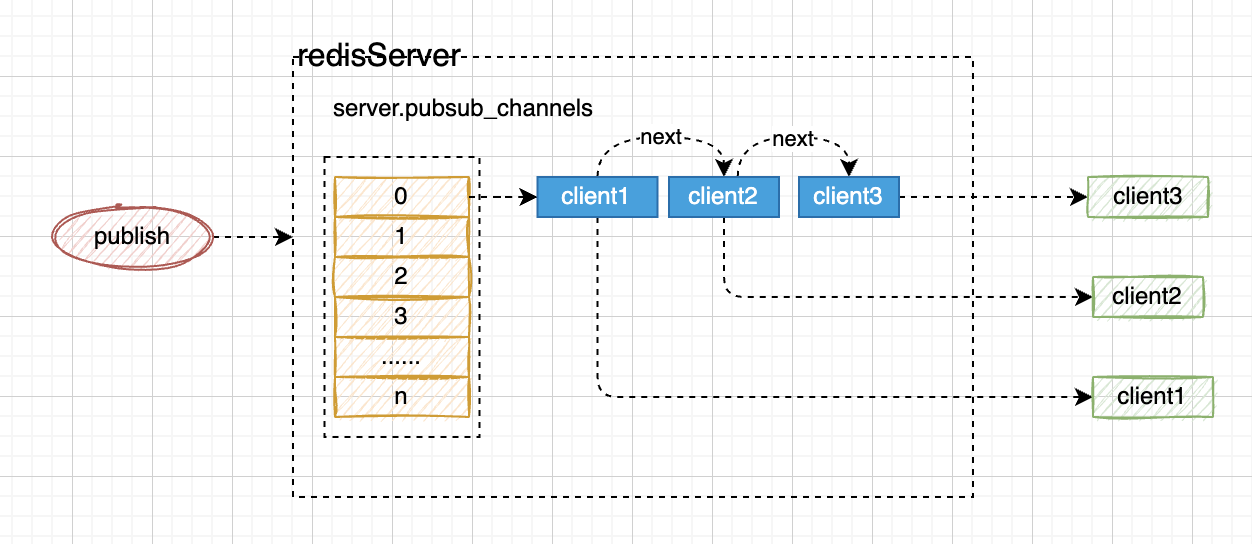
- redis的订阅与发布通过server.pubsub_channels来实现的;
- 当客户端发起subscribe的命令的时候,会把客户端订阅的channels放入到server.pubsub_channels中,对应的channels通过hash路由到对应的桶,然后找到对应的channel,channel对应的value是一个链表,维护所有订阅的客户端;
- 当publish的时候,根据chanel找到对应的value,遍历所有的额客户端,并将publish的内容通知给订阅的客户端;
- 从原理上来看,发布时,订阅的服务必须在线,要不然消息就没了,redis不会存储这些消息;
- 这个适用于规则的发布,比如网关路由规则,规则引擎的动态规则包(比如我们之前用的drools)
redis的事务
redis中有事务的概念,但是大家不要把这个事务往mysql的事务上靠。
- redis的事务只是保证了多条命令的串行执行(执行过程中不会被别的命令插入)
- 并不能保证执行命令的原子性(原子性的保证,可以使用lua脚本)
- redis通过
multi和exec来实现事务multi指令告诉server中的client开启事务- 多条执行命令(命令并未执行,而是缓存了起来)
- 接收到
exec命令 后server中的client执行命令
我们看下源码:
/**
* server接收到multi指令后的动作
* @param c
*/
void multiCommand(client *c) {
//已开启,直接拦截
if (c->flags & CLIENT_MULTI) {
addReplyError(c,"MULTI calls can not be nested");
return;
}
//将客户端标记为CLIENT_MULTI
c->flags |= CLIENT_MULTI;
addReply(c,shared.ok);
}
在server.c中
/**
* @brief 命令执行
* @param c 客户端
* @return int
*/
int processCommand(client *c) {
/**
*
* 开启了事务(CLIENT_MULTI)直接放入Multi队列
*
*/
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand){
queueMultiCommand(c);
addReply(c,shared.queued);
}
}
/**
* 添加命令到事务队列
* @param c
*/
void queueMultiCommand(client *c) {
multiCmd *mc;
int j;
c->mstate.commands = zrealloc(c->mstate.commands,
sizeof(multiCmd)*(c->mstate.count+1));
mc = c->mstate.commands+c->mstate.count;
mc->cmd = c->cmd;
mc->argc = c->argc;
mc->argv = zmalloc(sizeof(robj*)*c->argc);
//最终将客户端接收的命令都copy到mc->argv
memcpy(mc->argv,c->argv,sizeof(robj*)*c->argc);
for (j = 0; j < c->argc; j++)
incrRefCount(mc->argv[j]);
c->mstate.count++;
c->mstate.cmd_flags |= c->cmd->flags;
}
/**
* 命令执行
* @param c
*/
void execCommand(client *c) {
//关键点,遍历,并执行,由于redis命令执行是单线程处理,所以在多个客户端的时候,能保证串行执行
for (j = 0; j < c->mstate.count; j++) {
c->argc = c->mstate.commands[j].argc;
c->argv = c->mstate.commands[j].argv;
c->cmd = c->mstate.commands[j].cmd;
call(c,server.loading ? CMD_CALL_NONE : CMD_CALL_FULL);
/* Commands may alter argc/argv, restore mstate. */
c->mstate.commands[j].argc = c->argc;
c->mstate.commands[j].argv = c->argv;
c->mstate.commands[j].cmd = c->cmd;
}
discardTransaction(c);
} redis怎么用lua脚本保证操作的原子性呢,看一个示例,
/**
* redis自增并续期过期时间的原子操作
* @param key
* @param expireTime
* @return
*/
public static Long incrByAtom(String key,int expireTime){
StringBuffer luaScript = new StringBuffer();
//lua脚本
luaScript.append("local count = redis.call('incrby', KEYS[1],1) ")
.append(" redis.call('expire', KEYS[1],ARGV[1]) ")
.append(" return count ")
;
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(luaScript.toString(), Long.class);
//redisTemplate 调用
Object result = redisTemplate.execute(redisScript, Collections.singletonList(key), String.valueOf(expireTime));
if (Objects.isNull(result)){
return null;
}
return Long.valueOf(result.toString());
}也可以直接使用redisson,它内部封装了很多的lua脚本(不会写lua脚本,直接翻它的代码)
redis的数据淘汰机制
redis是一个内存数据库,当内存满了,redis是如何淘汰的呢?
淘汰触发机制
- 惰性删除(key过期的情况)
- 定期删除(采集过期key)
- 内存淘汰(执行命令前,发现内存超过阈值触发)
惰性删除
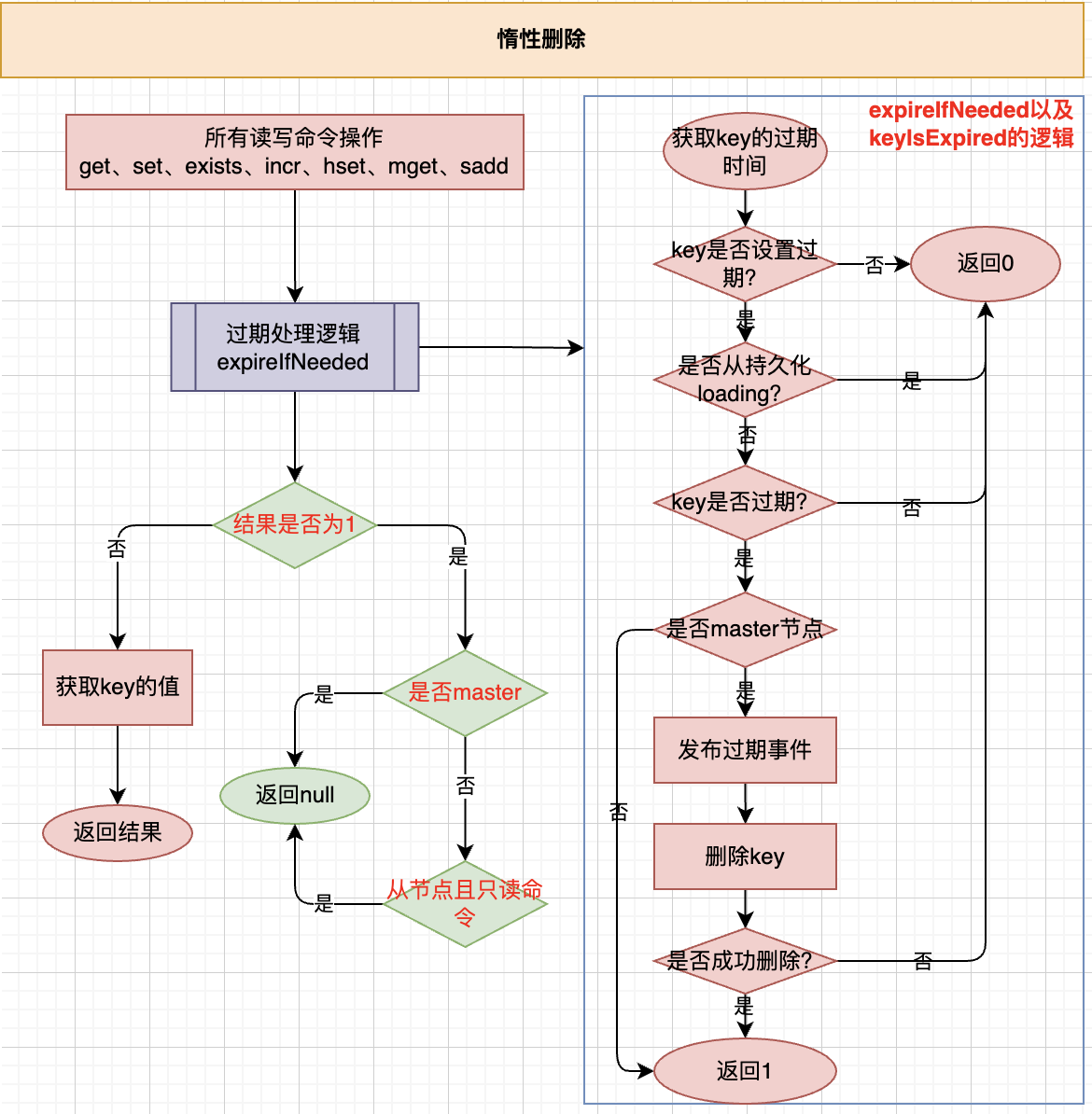
- 请求才会触发(不请求不会触发)
- 通过expireifNeeded函数处理
定期清理
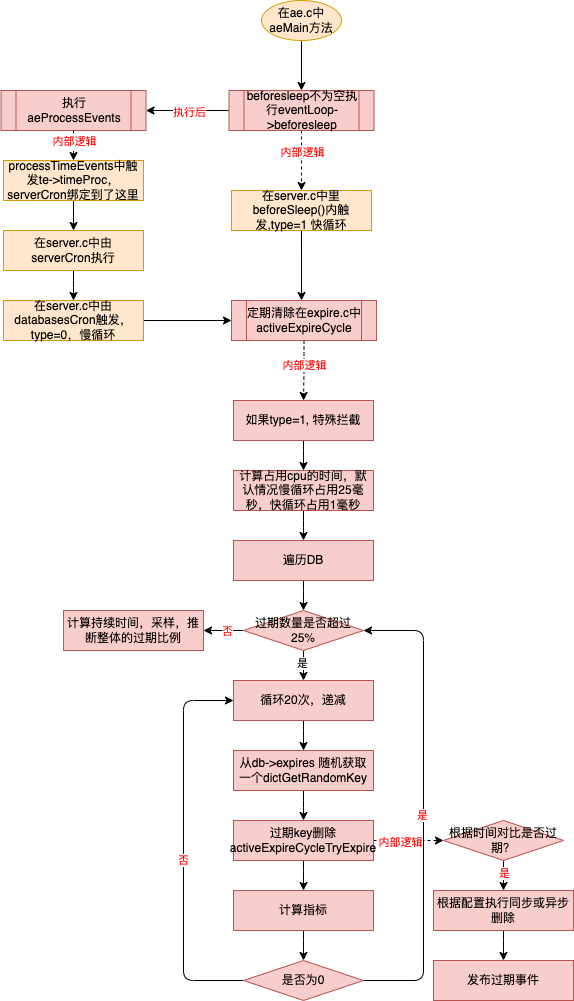
- 在beforesleep 中执行慢循环
- 一次只占用1毫秒的cpu时间片
- 在aeProcessEvents中执行慢循环
- 一次最多占用25毫秒(通过hz=10计算出来的)的cpu时间片
- 过期数量超过25%,执行20次循环
- 每次循环随机获取数据,计算占比
内存淘汰
Redis的几种淘汰策略:
-
noeviction 无过期策略,内存满了就直接异常
-
volatile-lru 对有过期时间的key进行lru淘汰(越长时间没有被访问,越容易被淘汰)
-
allkeys-lru 对全局的key按LRU进行淘汰(越长时间没有被访问,越容易被淘汰)
-
volatile-lfu 对有过期时间的key进行lfu淘汰(经常不被访问的,越容易被淘汰)
-
allkeys-lfu 对全局的key进行lfu淘汰(经常不被访问的,越容易被淘汰)
-
volatile-random 对有过期时间的key进行随机淘汰
-
allkeys-random 对有所有的key进行随机淘汰
-
volatile-ttl 按时间进行过期淘汰
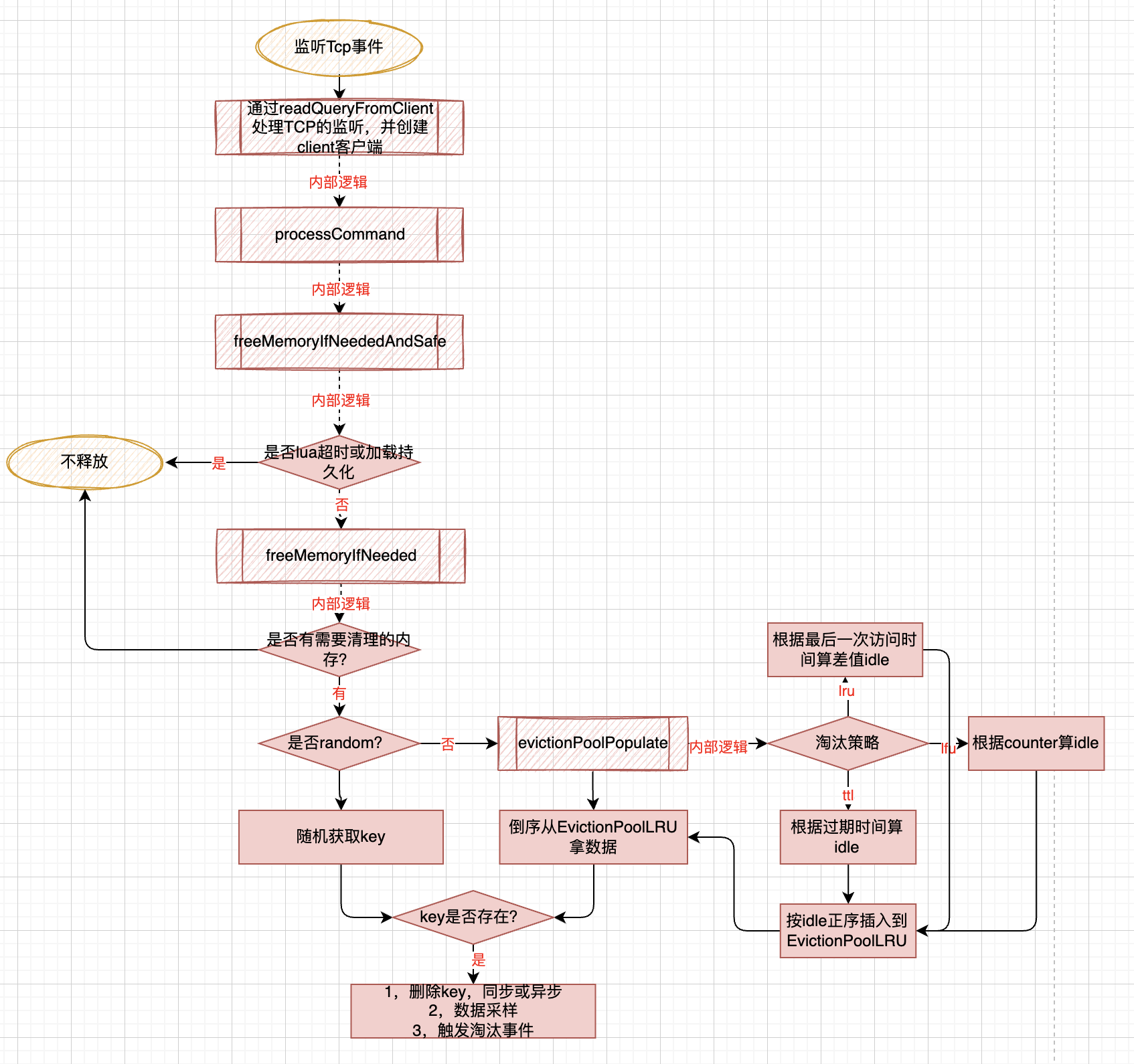
在freeMemoryIfNeeded中
- 从库不处理
- 计算需要释放的空间mem_tofree,如果没有需要释放的就不处理(这里会把主从复制的缓冲区减掉)
- noeviction 淘汰策略直接返回,失败;
- 如果已用的内存超了,随机采样key,进行释放,直到释放的空间小于要释放的内存;
- LRU、LFU、TTL 这三种策略是一种处理
- RANDOM 策略处理
- 根据采样到的key进行删除
对于LRU/LFU/TTL evictionPoolPopulate 函数是核心,核心思想就是随机采样后,计算采样数据的idle值
-
对LRU,idle是现在到上次访问的时间差,操作val对象的robj,这个值是记录在robj中的lru里
-
对LFU,idle是255-counter,counter是根据访问计算出来的衰减值,操作val对象的robj
-
对TTL, idle是db->expires里存储的dictEntry,val是到期日期
//所有的操作都会调用lookupKey,在这里会更新LFU的访问频次或LRU的时钟
robj *lookupKey(redisDb *db, robj *key, int flags) {
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
//更新访问频次
updateLFU(val);
} else {
//更新LRU的时钟,这个简单
val->lru = LRU_CLOCK();
}
}
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
/**
* 相当于每1毫秒获取一次时钟
*/
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
atomicGet(server.lruclock,lruclock);
} else {
lruclock = getLRUClock();
}
return lruclock;
}
/**
* @brief 更新LFU高16位的时钟和后8位记录的数
* @param val
*/
void updateLFU(robj *val) {
//获取counter,用了计数衰减的
unsigned long counter = LFUDecrAndReturn(val);
//更新LRU的后8位,也就是LFU的counter,LFU 使用近似计数法,counter越大,使用了对数的思想
counter = LFULogIncr(counter);
/**
* 获取分钟级的时间,左移8位(占高16位)
* 低8位couter占用
*/
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
/**
* @brief 更新LRU的后8位,也就是LFU的counter
* LFU 使用近似计数法,counter越大,使用了对数的思想
* @param counter
* @return uint8_t
*/
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
/**
* @brief rand()随机生成一个0~RAND_MAX 的随机数
* r的范围是0~1
*/
double r = (double)rand()/RAND_MAX;
//
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
/**
* server.lfu_log_factor 默认为10
* baseval 越大 p的值就越小
*/
double p = 1.0/(baseval*server.lfu_log_factor+1);
/**
* r是随机生成的0~1
* counter 是以5为起始点
* baseval=0 时: p的值为1 r的在1以下的概率为100%
* baseval=1 时: p的值为0.0909 r的在0.09以下的概率只有约9% 10次counter+1
* baseval=2 时: p的值为0.0476 r的在0.0476以下的概率只有约4.8% 20次counter+1
* baseval=3 时: p的值为0.0322 r的在0.0322以下的概率只有约3.2% 30次counter+1
* baseval=4 时: p的值为0.0244 r的在0.0244以下的概率只有约2.4% 40次counter+1
* baseval=5 时: p的值约0.0196 r的在0.0196 以下的概率只有约2% 50次counter+1
* baseval=10 时:p的值约0.0099 r的在0.0099 以下的概率只有约1% 100次才可能加1次
* baseval=100时:p的值约0.000999 r的在0.000999 以下的概率只有约0.1% 1000次才可能加1
* baseval=200时:p的值约0.0005 r的在0.0005 以下的概率只有约0.05% 2000次才可能加1
* 想达到100的baseval总次数为(10+20+30+40+...+1000)=49*1000+500 约 5万次
* 想达到200的baseval总次数为 (10+20+30+40+...+2000) = 99*2000+1000 约20万次
*/
if (r < p) counter++;
return counter;
}- LFU 使用lru的24位,低8位记录统计次数,高16位记录分钟级的访问时间
- LFU 给一个初始 LFU_INIT_VAL 防止高频数据刚插入因为counter太小而被淘汰;
- LFU 使用近似计数算法,counter越大,counter增加的几率反而越小(防止热点数据被刷上去以后淘汰不了)
redis的持久化机制
三种持久化模式
- RDB
- AOF
- RDB与AOF混合模式
RDB
rdb文件示意图

-
在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)
-
rdb 是一个非常紧凑的二进制文件
-
rdb适合灾难恢复,主从复制
-
异步rdb可以最大化redis的性能,rdb操作是会从主进程fork一个子进程(fork的过程中创建快照表会阻塞主进程),不会阻塞主进程,但是占用磁盘IO;
-
rdb写的只是当时那个时间点的快照,并不会追加增量数据
-
rdb写后处理通过下个周期触发
通过参数配置
# 表示900秒内有一个键改动,就会执行rdb save 900 1 # 表示300秒内有10个键改动,就会执行rdb save 300 10 # 表示60秒内有1万个键改动,就会执行rdb save 60 10000 # redis通过LZF算法对RDB文件进行压缩,会消耗子进程的cpu资源(多核,物理核、逻辑核有区别),如果是单核就会影响主进程 rdbcompression yes # redis默认使用CRC64的算法对RDB文件进行完整性校验 rdbchecksum yesrdb处理流程

AOF
正常AOF
- 记录每一个收到的写操作命令
- 实时写入(根据appendfsync的配置,对应的配置如下)
- aways 有数据改动就把数据刷入磁盘,性能相对最差,但最安全
- everysec 每隔1秒刷一次数据,redis默认的,也是redis推荐的
- no 不主动刷,什么时候刷数据,取决于操作系统,大多数linux 30秒提交一次
- 将执行命令组装成aof内容buf,AOF 会将过期时间由相对转成绝对(重点)
- 如果AOF开启且未重写的情况下,将刚组装的buf放入到server.aof_buf 后,正在重写aof,将buf写到 server.aof_rewrite_buf_blocks中
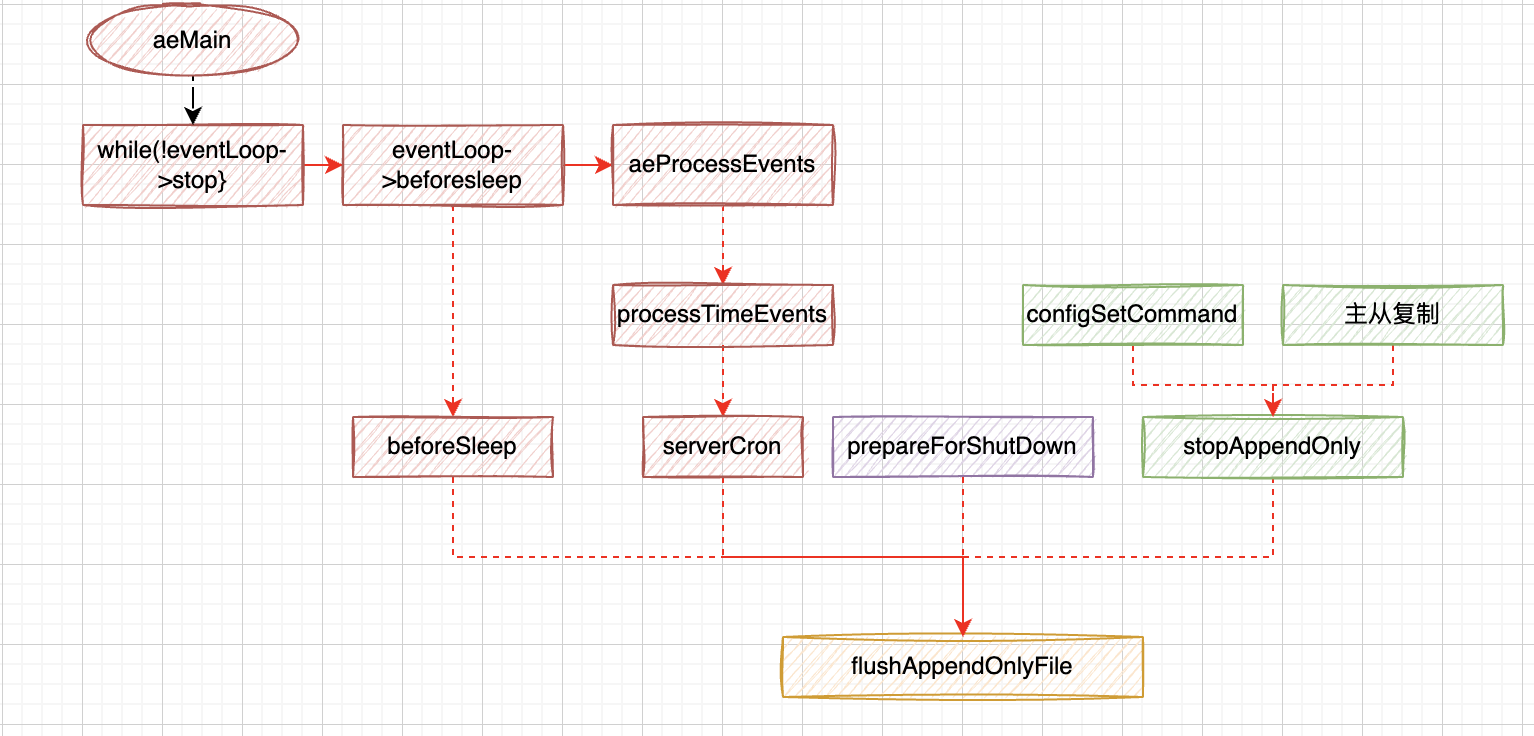
aof有几个场景的写入:
- 在主流程的循环体里
- 在循环执行前的beforesleep里
- 在serverCron里
- 准备停止之前调用一次
- 通过configSetCommand设置
- 主从复制
AOF重写
触发时机:
- 在周期性循环里进行
- 通过命令调用执行aof重写
- 一个是bgrewriteaofCommand
- 一个是configSetCommand
- 主从复制时触发
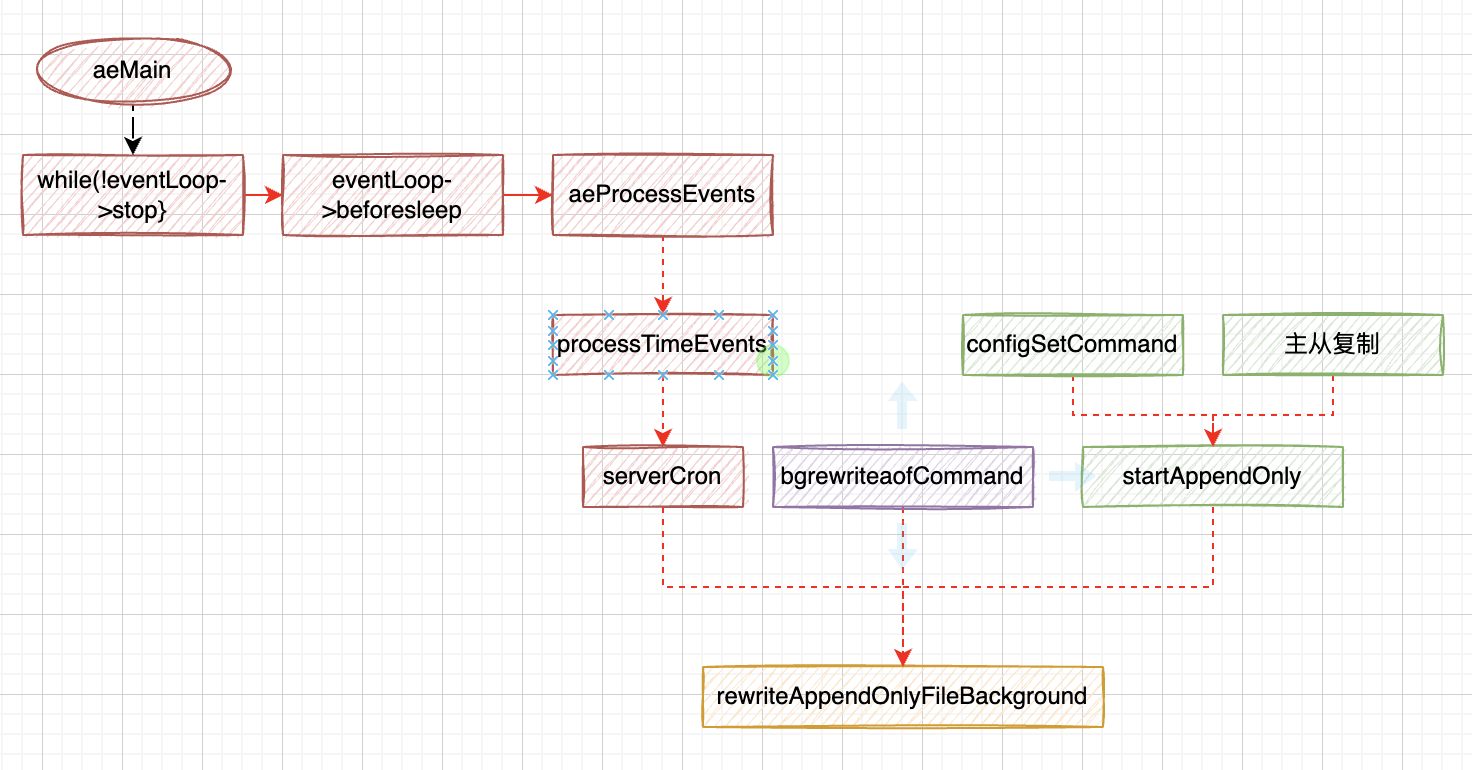
aof重写过程:
- aof的重写过程和bgsave方式的rdb差不多的过程差不多
- aof 重写有两种模式,一种是先写rdb,再追加aof(混合模式),一种是一路aof格式
- aof在将虚拟内存空间里的数据写完以后,会通过wait轮训从管道server.aof_pipe_read_data_from_parent里获取增量更新的数据
- 增量更新在第一小节的时候,有个aofChildWriteDiffData处理器(通过FileEvent机制写入)
- 然后aof 子父进程发送ack确认消息
- 最后再次通过rioWrite 将ack期间追加的数据补救回来
- 最后将rof的临时文件重命名为temp-rewriteaof-bg-进程id.aof
redis为什么要进行aof重写呢?
- aof记录的是所有的修改操作,随着运行越来越大;
- redis作为一个缓存数据库,很多的数据是有有效期的,可能30秒后之前的键值就无效;
- 这些失效的数据,对于aof后续的恢复来说是大部分都是执行无效的数据,会导致效能过低;
- 磁盘的的占用也是一个问题,其实rdb也是这个理;
为什么aof和rdb要后台子进程运行?
- 子进程通过页映射表来读取主进程的物理数据,使用子进程,一是防止阻塞主进程,二是省去了数据的拷贝;
- 对于redis来说,对外提供高性能的服务是核心,aof和rdb是辅助性的维护手段;
- 简单来说非核心业务不要影响核心业务;
redis的rehash
首先我们了解下hash
- 在单个db中全局保存redis的key
- 可以往上看下redis的基本结构
其次了解下rehash的目的
- 扩容
- 防止key过多时,hash冲突,链化(redis采用拉链法解决hash冲突)导致的查询性能下降
- 5倍容量后才会触发扩容
- 往上去最近的2的n次方
- 缩容
- 大量key过期后,hash过大,会有大量的空闲空间
- 1/10以下的使用量才会触发
rehash的触发时机
- 扩容时机
- 在添加添加元素的时候去判断是否需要扩容
- 当used是size的5的倍的时候才触发扩容
- 缩容时机
- 在周期性任务,serverCron 的databaseCron 函数中
- 当已用小于1/10,则触发缩容
ps: 当有持久化任务时不会触发
rehash的执行操作
- redis的rehash并不是一次触发就就全部执行完,而是通过周期性的动作执行完的,所以叫渐进式hash
- rehash的时候,是吧ht[0]的数据搬迁到ht[1]中
- 搬迁以后会根据hash重新选择对应的桶
- 客户端发起的所有的dict的操作方法(不管是get、set、等都绕不开),一次只搬迁1个桶
- redis在轮训的时候serverCron中的调用,一次执行1毫秒,最少搬迁100个桶
- rehash的时候,如果在此触碰rehash,直接拦截(所以不会出现rehash过程中再次rehash)
redis集群
有三种模式:主从模式、哨兵模式、集群模式;
主从模式
redis最原始的模式,master宕机需要手动配置将slave转为master。
- 主从模式并不能保证高可用(最起码从发现宕机到手动切换这段时间,写是不可用)
- 主节点写操作导致数据数据变化时,会主动将数据推送给从节点;
- 主从模式,一主多从,数据单向流动;
- 主节点挂了以后,写不可用(读可用),直到手动改了配置
- 灵活性较低
主从复制一共有三种模式:
- (重新)全量复制
- slave订阅,保存了master的端口、地址和密码
- 通过
syncWithMaster进行认证 - 通过周期任务+状态机(如果主阻塞,状态机就会超时)
- master做了优化,具体代码在updateSlavesWaitingBgsave
- 检查所有的slave,给所有的slave状态为等待bgsave结束的salve发送rdb文件
- 最终由sendBulkToSlave 将rdb发送到slave上
- slave通过
slaveTryPartialResynchronization发送psync和接收psync- 返回
FULLRESYNC会进行重新全量复制 - 返回
CONTINUE会进行增量同步
- 返回
- 实时复制
- 在server.c中call方法里调用propagate函数,再调用
replicationFeedSlaves - 先通过
feedReplicationBacklog加入到server.repl_backlog - 再调用
addReplyMultiBulkLen函数进行实时同步
- 在server.c中call方法里调用propagate函数,再调用
- 增量复制(这块还是有点没理清,如果差量的数据如何同步过来?后续再做个详解)
- 通过
slaveTryPartialResynchronization返回CONTINUE进行增量同步 - 在
replicationResurrectCachedMaster里- 通过绑定处理器
readQueryFromClient注册一个FileEvent事件,用来读取接收slave客户端到的信息 - 通过绑定处理
sendReplyToClient注册一个FileEvent响应给master
- 通过绑定处理器
- 通过
这里就不贴源码了,看下主从复制的时序图,以及对应的状态流转
对应的时序图,两步:
- 执行replicaof命令
- 周期任务里根据状态流转,这个过程也会注册一些事件,又会进行一次轮训
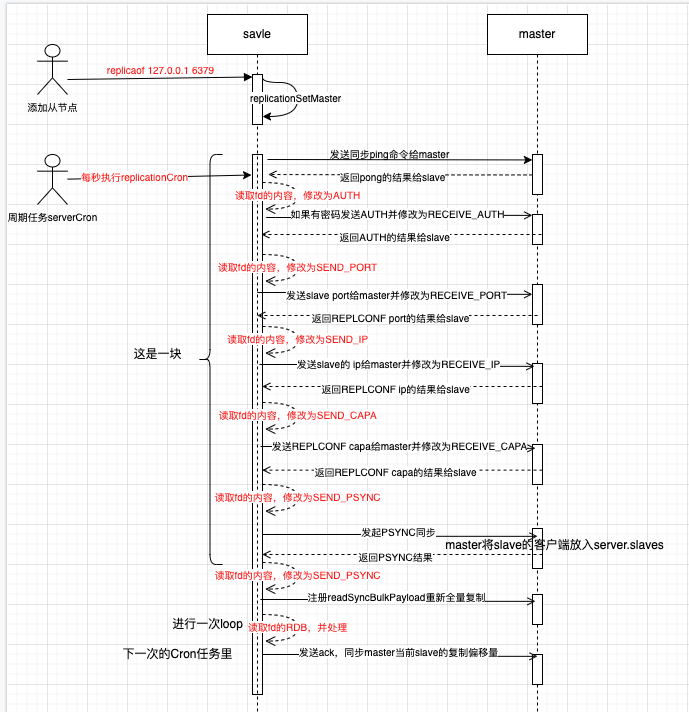
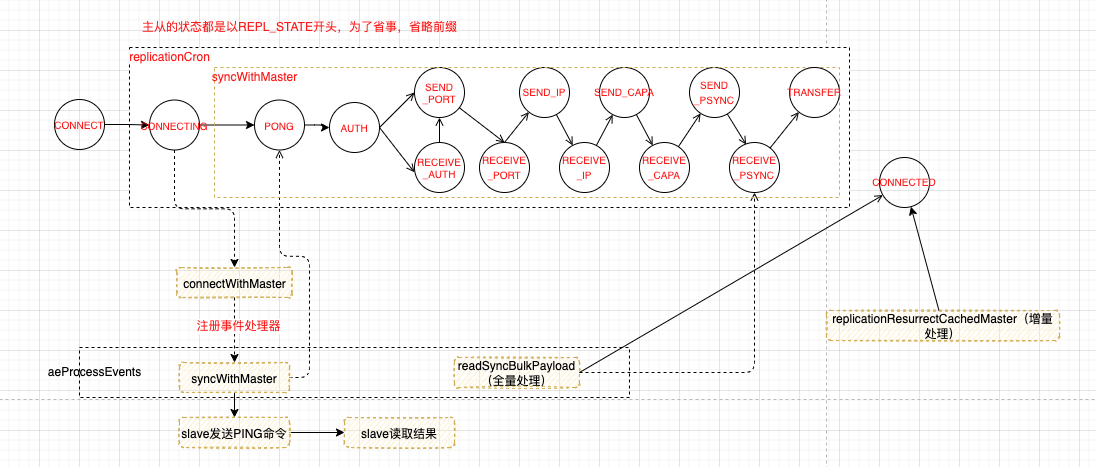
哨兵模式
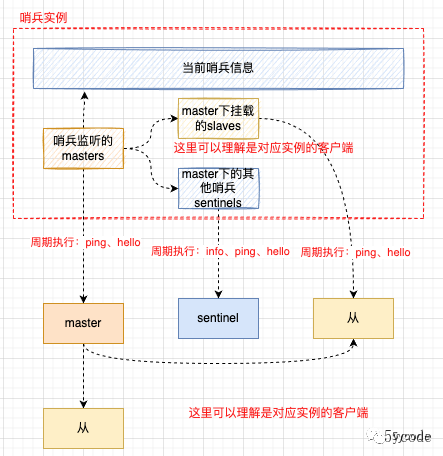
- redis的高可用支持(将主从切换由手动改成了通过哨兵监听并投票选举切换)
- 用于监控主机状态
- 使用raft协议来选举,达成共识
- 发现主节点fail的哨兵,成为哨兵的leader,标记主节点主观线下
- 其他哨兵会跟着投票,达成一致后标记为客观下线
- 然后再选举leader,又会进行投票
- 达成一致后,进行主从切换
集群模式
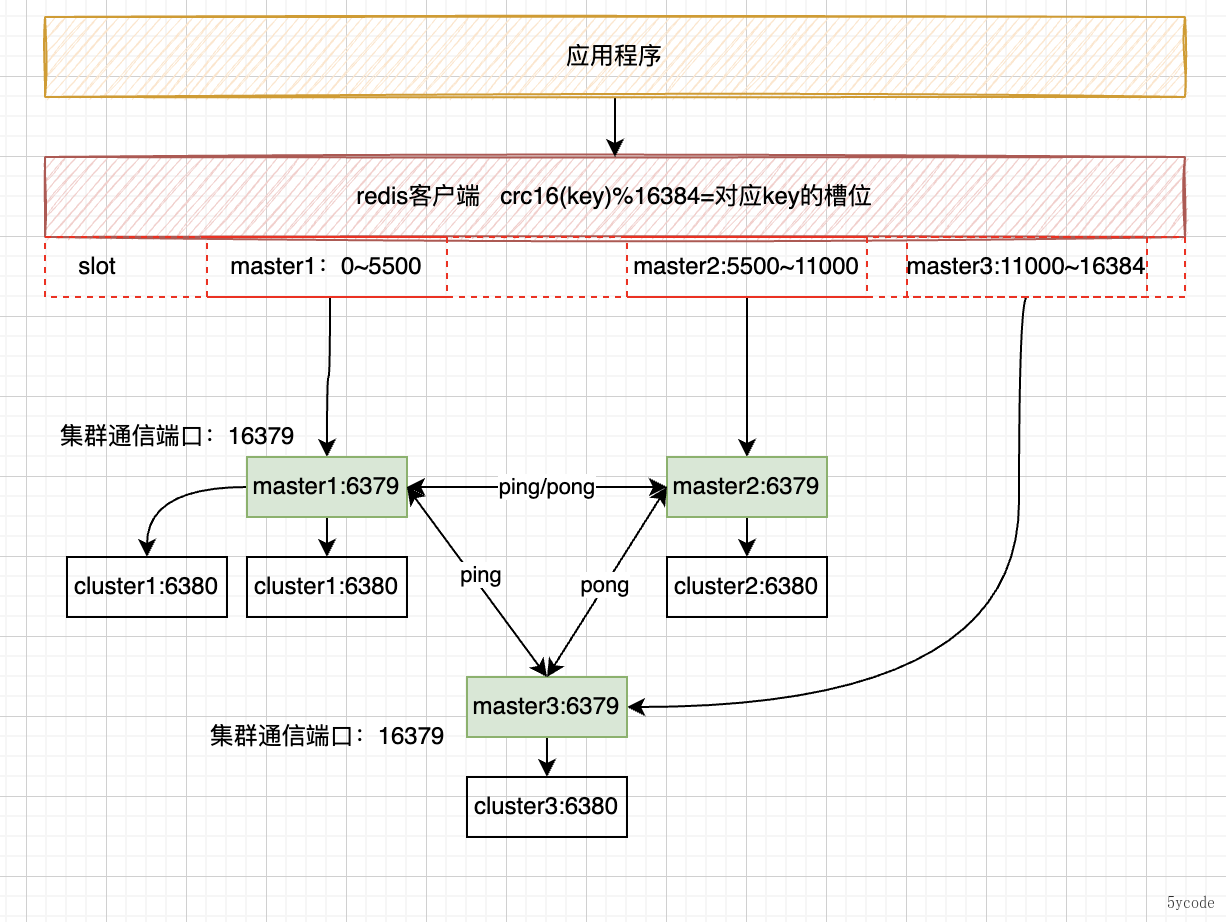
- 去中心化的集群方案,内置哨兵
- 为了解决单redis写的性能问题,将数据分片
- 使用CRC16计算hash,一个集群包含16384个hash槽
- 集群启动对槽进行分配,分配槽和节点的关系;
- 通过迁移热点槽可以解决流量倾斜的问题;
- 适合并发量特别大的业务;
- 集群实现了AP
- 通过主从以及分区提供一定程度的可用性
- 通过节点超时防止脑裂
- 通过gosip协议达成最终一致性
常见问题
-
数据类型选择不合理
- 会导致存储空间过大,比如多字段存储用hash不用json
-
过期key订阅
- 到期后不会立即清除,考虑下redis的过期策略;
- redis产生expired的事件为过期key被删除的时候,而不是ttl变为0的时候;
-
大key优化
-
大key会产生的问题
- 占用网络IO和cpu,阻塞,比如有的key里存储十几MB的数据,多次查询,会阻塞其他的操作请求;
- 内存挤占过多,甚至会把未失效的清掉,比如自己用zset做的限流、数据没有及时删除,导致占用内存过多;
- 删除也会阻塞(使用异步删除unlink)
-
如何发现?
- 使用redis-rdb-tools 分析rdb文件,相对有些延迟;
- 使用bigkeys
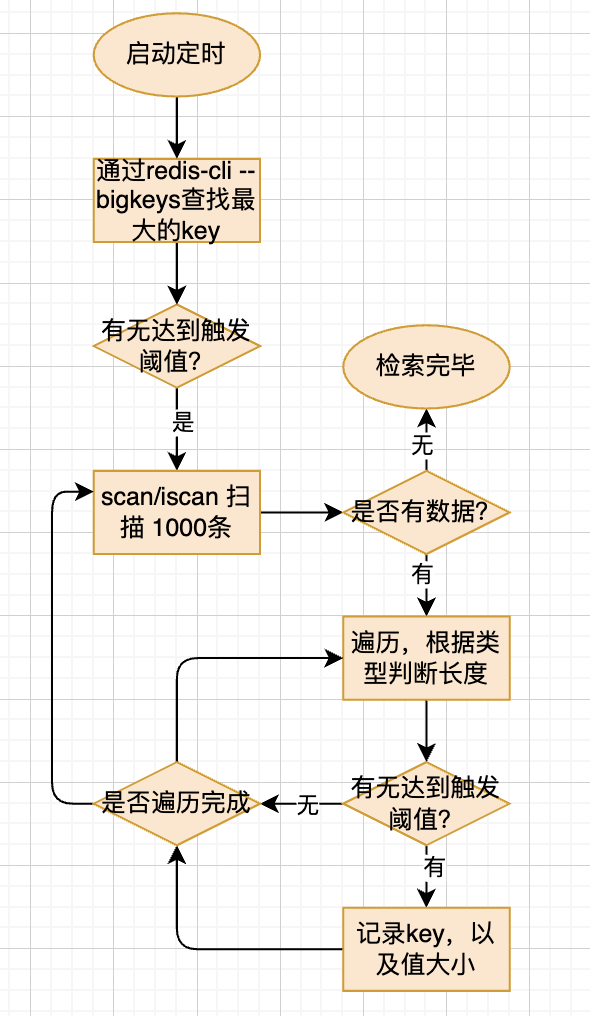
-
-
数据倾斜
- 集群某个节点热点数据过多,或者数据量较大
-
脑裂
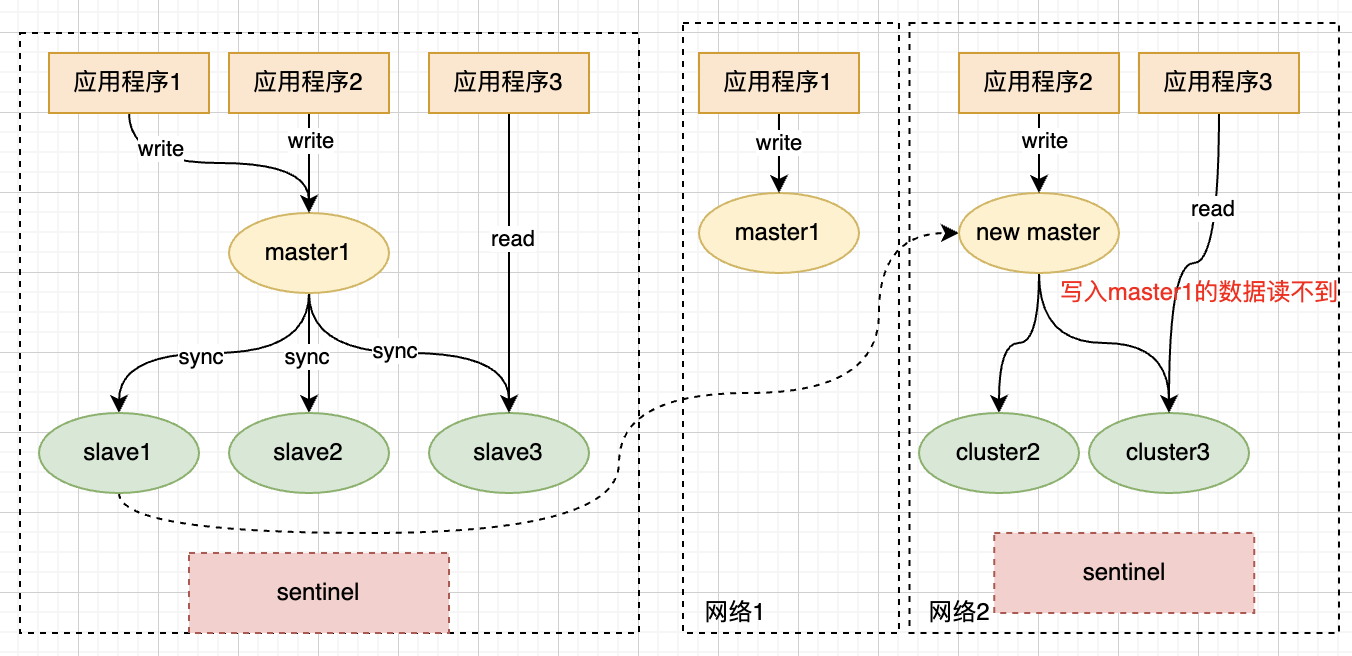
-
缓存击穿:并发量比较大的key,在某个时间点过期,导致流量都打到了db上;
- 加锁更新,流量阻塞在应用中;
- 后端异步写,比如key 10分钟过期,8~9分钟更新下异步过期时间;
- 如果数据的实时性要求不是那么高,可以加个本地缓存;
-
缓存穿透:缓存中不存在对应的数据,导致没所有的请求都打到了db上;
-
这种情况下主要是DDOS攻击
- 如果是文章或商品,直接将对应的数据放入到布隆过滤器
- 前端查询条件最好加密,不要使用自增id,让人寻找到规律
- 如果是异步刷缓存,就不要查DB,只到缓存这层就结束
- 如果不确保数据会进缓存,可以对db查不到的数据key进行null缓存(如果有新数据,业务得能刷新);
-
业务代码没有使用缓存
- 增加缓存
-
-
缓存雪崩:缓存服务宕机或者大批量缓存某一时刻过期,流量达到DB上后,会导致系统崩溃;
- 针对高并发系统,缓存服务一定要高可用;
- 同一时间到期的数据,加上随机值,让其均匀分布;
- 针对热点数据,后端异步刷新;
- 系统服务的熔断降级
-
阻塞
- 大量过期key到期导致的cpu过高
-
共用redis,非核心业务系统执行命令阻塞redis,导致核心业务不可用;
redis使用注意事项
- 不要永久性保存,哪怕我们将过期时间设置的长一点()
- 一定要考虑缓存失效的问题,失效后要有兜底方案;
- 普通的业务,可以使用旁路缓存,失效从数据库加载数据;
- 如果是流量特别高的应用,建议用定时任务或延迟队列异步将数据刷入redis;
- 做好集群分配
- 定期监测,防止流量倾斜
- 不要大批量设置同一时间点过期
- 到期后占用比例比较高,在清理时,会占用cpu过多的时间,阻塞正常的业务请求;
- 单个缓存不要过大,最好不要超过10k;
- 过大网络io会比较高,阻塞redis;
- 尽可能通过hash存储对象,不要一个个的分开存储或者直接json序列化(一个是省内存,一个是效率)
- 分布式id生成,尽量不要使用redis做序列自增
- 防止集群切换、或者redis挂掉导致的主键重复;
- redis挂掉时,如何处理?如何不会主键重复?
- 谁用分布式id,尽可能保证多态机器的相对有序
- 不要使用容易阻塞的命令,一般都是精确定位,不要模糊匹配;
- 比如keys,建议配置文件中通过rename屏蔽该命令
redis系列文章
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了
redis源码阅读五-为什么大量过期key会阻塞redis?
本文是Redis源码剖析系列博文,有想深入学习Redis的同学,欢迎star和关注; Redis中文注解版:https://github.com/yxkong/redis/tree/5.0 如果觉得本文对你有用,欢迎一键三连; 同时可以关注微信公众号5ycode获取第一时间的更新哦;


文章评论