上周分享了一篇文章(DDD的应用框架实践分享) 周五又在内部将给大家分享了下。现将分享内容与大家分享。
传统开发的弊病:
-
通过事务脚本模式来开发需求;
-
开发人员热衷于技术并通过技术手段解决问题,而不是深入思考和设计业务的走向;
-
过于重视数据库,围绕数据库和数据模型进行建模,按数据流程进行建模;
-
按技术视角进行业务命名,导致后续迭代以及人员更替时,产品和技术无法对齐;
-
随着业务的发展,到后续业务、技术无法沟通,各种不理解;
-
业务希望技术出排期,技术得撸代码,耗费精力;
-
代码开发的过程中技术和业务耦合,一个场景一个服务,代码流水线;
-
因为技术的问题会导致业务流程的中断,导致异常问题过多;
-
过度方案太多,没有定期消除,导致后续的代码越来越难维护;
-
业务只加需求,不减过期的需求,导致软件越来越臃肿;
DDD解决了什么?
-
通用语言,让开发和业务在语言上统一;
-
战略设计(业务和开发都能看到的软件模型)
-
边界划分(通过限界上下文来划分,在不同的情景下域的作用是不同)
-
领域划分(通过域来确定业务领域,包含核心域、子域、支撑域)
-
分层架构(整洁架构)
-
战术设计
-
聚合(值对象,实体,聚合根)
-
领域事件
最终要达到的目的:
-
业务和技术能够通过领域模型建立通用语言(业务和技术的沟通无障碍);
-
业务边界清晰(微服务的拆分);
-
业务模型独立且模型具备可测试性;
-
技术实现独立,可以随着业务的发展不断的更迭;
名词解析
事务脚本-面向过程
-
事务:执行的业务
-
脚本 一组系统执行的操作,和用户的逻辑关联;
根据接口请求,将业务逻辑通过面向过程组织为解决方案的过程;特点:
-
简单 (仅依赖面向对象语言的少量功能)
-
快速 开发快、上线快
-
扩展性查
-
改动以后测试性差
-
业务复杂后,代码容易变成“大泥球”,系统腐化速度和复杂性呈指数级上升
领域模型
通过面向对象的设计,将业务实现模型化(将类的状态和行为分离);
特点:
-
还原现实世界(复杂)
-
责任清晰
-
边界清晰
-
完全面向对象,状态和行为分离;
-
扩展性强
-
测试性强
-
简单的业务用领域模型反而复杂了;
DDD
是对面向对象设计的改进,开发复杂业务逻辑的一种方式,但不是银弹。
特点:
-
通过领域划分有助于把应用程序分解为服务;
-
每个服务都有自己的领域模型;
-
限界上下文清晰
实体
具有持久化ID的对象,能唯一标识一个条记录的;
特点:
-
标识(identity)唯一不可变,且能区分出具体的事物
-
连续性(continuity),贯穿整个生命周期
-
只有根实体对外暴露(但不排除一些为了冗余而暴露别的信息)
在我们的系统里,用户实体的标识:包含id和租户,只有这两个组合我们才能唯一识别出这个用户
public class CustomerId {
private Long id;
private Integer tenantId;
public CustomerId(Long id, Integer tenantId) {
this.id = id;
this.tenantId = tenantId;
}
public boolean isRealName(){
if (Objects.isNull(this.id) || this.id == 0L){
return false;
}
return true;
}
}
值对象
⽤于描述状态的属性,特征,只关心对象是什么,不关注唯一性。
聚合根
把一组有相同生命周期、在业务上不可分离的实体和值对象放在一起;
领域事件
由特定领域,因触发一个动作而触发的发生在过去的行为事件
特点:
-
动作(一个行为的发生产生的)
-
已发生
工厂
负责聚合根、实体的创建,以及各层之间数据的转化;如:
-
adapter 到领域层的数据转化
-
基础设施层到领域的转换
CQRS
是将 command 与 query 分离的一种模式。CQRS 将系统中的操作分为两类,即「命令」(Command) 与「查询」(Query)。命令则是对会引起数据发生变化操作的总称,即我们常说的新增,更新,删除这些操作,都是命令。而查询则和字面意思一样,即不会对数据产生变化的操作,只是按照某些条件查找数据。
CQRS 的核心思想是将这两类不同的操作进行分离,然后在两个独立的「服务」中实现。这里的「服务」一般是指两个独立部署的应用。
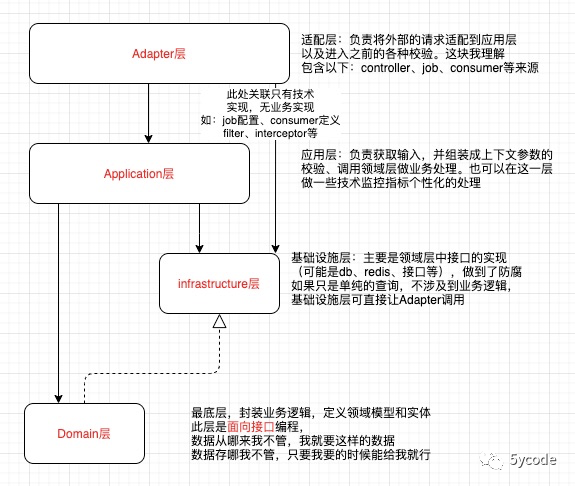
架构
DDD分层架构
DDD分层架构中有很重要的依赖原则:每层只能与位于下方的层发生耦合,类似于网络的7层或TCP/IP的4层模型架构,每一层各司其职,并且只关心向下一层的实现,而不会出现各层耦合。
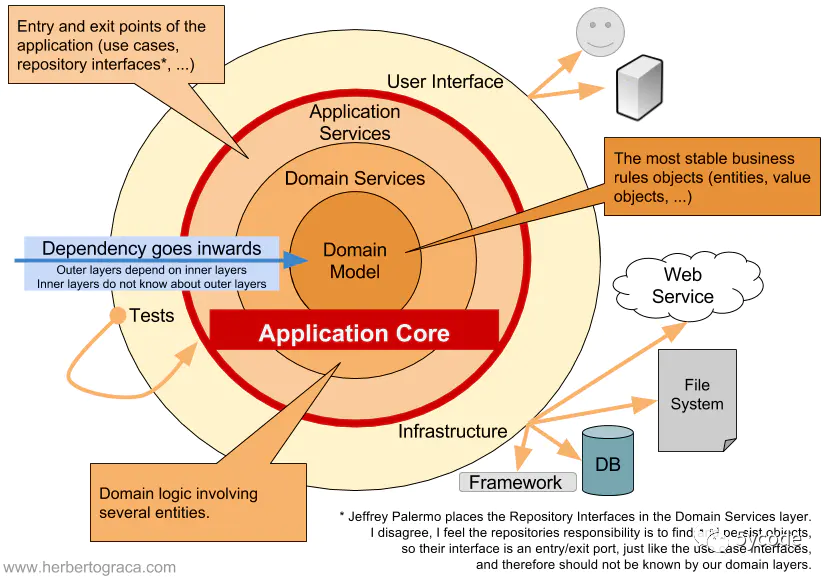
洋葱架构
同心圆代表软件的不同部分,从里向外依次是领域模型,领域服务,应用服务和外层的基础设施和用户终端。洋葱架构根据依赖原则,定义了各层的依赖关系,越往里依赖程度越低,代码级别越高,越是核心能力。外圆代码依赖只能指向内圆,内圆不需要知道外圆的情况,
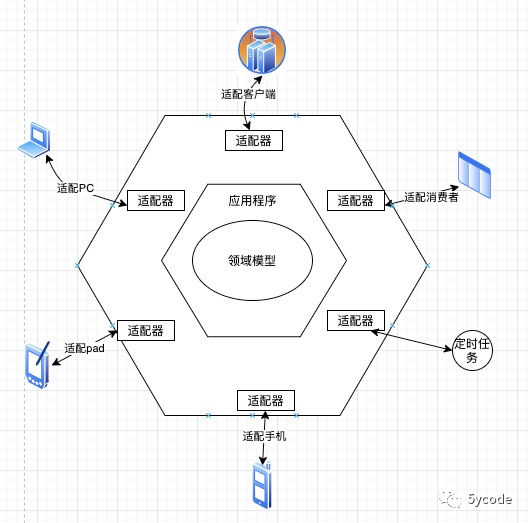
六边形架构
将应用分为内六边形和外六边形两层,内六边形实现应用的核心业务逻辑。外六边形完成外部应用,基础资源等的交互和访问,对于与不同的外部系统交互,由外六边形的适配器负责协议转换,保证内六边形业务逻辑的干净。
四种领域模型
-
失血模型:领域对象只包含setter和getter方法,业务逻辑放到service
-
贫血模型:包含属性的getter/stter和所有业务逻辑;
-
充血模型:包含属性的getter/stter和所有业务逻辑,再加上与数据库的操作。这是DDD提倡的模型
-
胀⾎模型,删除Service层,所有逻辑都放到模型中,模型直接对接web层
通过什么手段来落地?
-
事件风暴
-
用例+用户故事
我们是怎么做的?
-
使用半贫血模型;领域实体里包getter和setter,包含部分共用的业务逻辑,但不包含所有的业务逻辑;
-
复杂业务逻辑通过service构建的领域服务来处理;
-
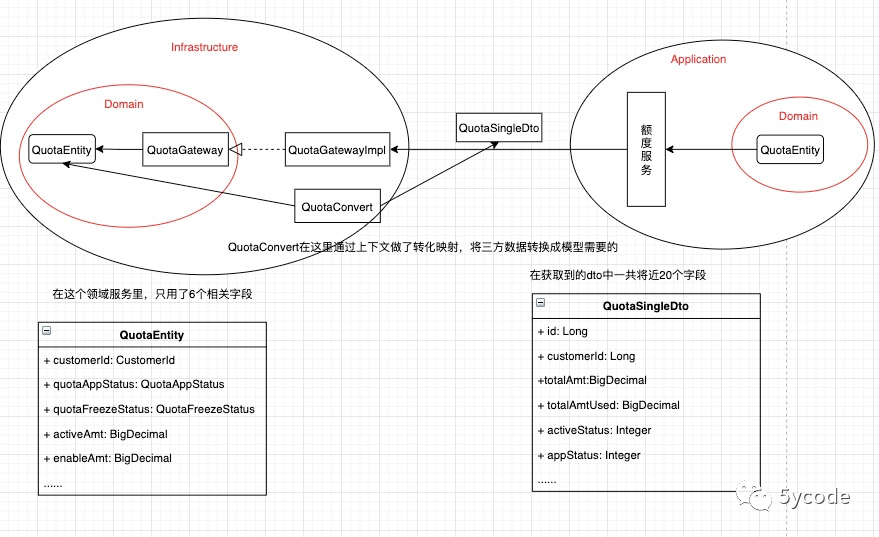
domain作为底层,依赖倒置基础设施层;
-
domain层通过gateway,做了一层防腐,gateway就是一组接口,具体实现根据实际情况选择,db、缓存、rpc、组合等;
-
复杂业务使用领域服务构建,简单业务直接应用层调用基础设施层;
分享后的大家问的几个问题
-
事务如何添加?
-
如果整个领域服务是一个事务,则在application层进行加事务,在application里需要注意,不要破坏领域;
-
如果只是其中领域服务的一个小方法,可以在gateway的实现里实现;
-
性能问题如何解决?性能属于技术问题,和业务无关;
-
比如常见的CQRS,将写和读分离,写异步
-
先写redis再写数据库
-
外部调用短连接变长链接;
-
事实数据做宽表;
-
事件驱动
-
采用哪种架构(六边形、洋葱架构)
-
最核心的整洁架构+DDD的分层架构,并没有特别严格;
-
最核心的是业务逻辑和与模型;
-
随着业务的发展与技术发展不断的适配;
参考:
https://blog.csdn.net/significantfrank/article/details/110934799
https://www.cnblogs.com/jiyukai/p/14830869.html
https://zhuanlan.zhihu.com/p/115685384


文章评论